存储与检索
生活中的一大痛苦是每个人对事物的命名都有些错误。因此,这使得世界上的一切比如果用不同的名称来命名时更难以理解。计算机并不是主要以进行算术运算的方式进行计算。[…] 它们主要是文件系统。
理查德·费曼,《特立独行的思维》研讨会(1985)
在最基本的层面上,数据库需要做两件事:当您给它一些数据时,它应该存储这些数据,而当您稍后再次询问时,它应该将数据还给您。
在第三章中,我们讨论了数据模型和查询语言——即您向数据库提供数据的格式,以及您稍后可以请求数据的接口。在本章中,我们从数据库的角度讨论相同的内容:数据库如何存储您提供的数据,以及当您请求数据时它如何再次找到这些数据。
作为应用程序开发者,您为什么要关心数据库如何在内部处理存储和检索?您可能不会从头开始实现自己的存储引擎,但您确实需要从众多可用的存储引擎中选择一个适合您应用程序的引擎。为了配置存储引擎以在您的工作负载上表现良好,您需要大致了解存储引擎在后台所做的事情。
特别是,针对事务工作负载(OLTP)优化的存储引擎与针对分析优化的存储引擎之间存在很大差异(我们在“分析系统与操作系统”中介绍了这种区别)。本章首先考察两类用于 OLTP 的存储引擎:写出不可变数据文件的日志结构存储引擎,以及像 B 树这样的就地更新数据的存储引擎。这些结构既用于键值存储,也用于辅助索引。
稍后在“分析的数据存储”中,我们将讨论一类针对分析优化的存储引擎,而在“多维和全文索引”中,我们将简要查看用于更高级查询(如文本检索)的索引。
OLTP 的存储和索引
考虑世界上最简单的数据库,它由两个 Bash 函数实现:
#!/bin/bash
db_set () {
echo "$1,$2" >> database
}
db_get () {
grep "^$1," database | sed -e "s/^$1,//" | tail -n 1
}这两个函数实现了一个键值存储。你可以调用 db_set key value ,它会将 key 和 value 存储在数据库中。键和值可以是你喜欢的(几乎)任何东西——例如,值可以是一个 JSON 文档。然后你可以调用 db_get key,它会查找与该特定键关联的最新值并返回它。
而且还能用:
$ db_set 12 '{"name":"London","attractions":["Big Ben","London Eye"]}'
$ db_set 42 '{"name":"San Francisco","attractions":["Golden Gate Bridge"]}'
$ db_get 42
{"name":"San Francisco","attractions":["Golden Gate Bridge"]}存储格式非常简单:一个文本文件,每行包含一个键值对,用逗号分隔(大致像一个 CSV 文件,忽略转义问题)。每次调用 db_set 都会追加到文件的末尾。如果你多次更新一个键,旧版本的值不会被覆盖——你需要查看文件中该键的最后一次出现以找到最新值(因此在 db_get 中有 tail -n 1 ):
$ db_set 42 '{"name":"San Francisco","attractions":["Exploratorium"]}'
$ db_get 42
{"name":"San Francisco","attractions":["Exploratorium"]}
$ cat database
12,{"name":"London","attractions":["Big Ben","London Eye"]}
42,{"name":"San Francisco","attractions":["Golden Gate Bridge"]}
42,{"name":"San Francisco","attractions":["Exploratorium"]}db_set 函数的性能实际上相当不错,尽管它非常简单,因为向文件追加内容通常是非常高效的。与 db_set 的做法类似,许多数据库内部使用日志,这是一种仅追加的数据文件。真正的数据库需要处理更多问题(例如处理并发写入、回收磁盘空间以防止日志无限增长,以及在崩溃恢复后处理写入了部分的记录),但基本原理是相同的。日志非常有用,我们将在本书中多次遇到它们。
注意
日志一词通常用于指代应用程序日志,其中应用程序输出描述正在发生的事情的文本。在本书中,日志是以更一般的意义使用的:磁盘上的仅追加记录序列。它不必是人类可读的;它可能是二进制的,仅供数据库系统内部使用。
另一方面,如果您的数据库中有大量记录, db_get 函数的性能将会变得非常糟糕。每次您想查找一个键时, db_get 都必须从头到尾扫描整个数据库文件,寻找该键的出现的地方。在算法术语中,查找的成本是 O(n):如果您将数据库中的记录数 n 加倍,查找所需的时间也会加倍。这并不好。
阅读笔记
时间复杂度可以参考
为了高效地找到数据库中特定键的值,我们需要一种不同的数据结构:索引。在本章中,我们将查看一系列索引结构,并比较它们;一般的想法是以特定的方式(例如,按某个键排序)来构造数据,以便更快地定位所需的数据。如果您想以几种不同的方式搜索相同的数据,您可能需要在数据的不同部分上创建几个不同的索引。
索引是从主数据派生出的附加结构。许多数据库允许您添加和删除索引,这不会影响数据库的内容;它只会影响查询的性能。维护附加结构会产生开销,尤其是在写入时。对于写入操作,简单地向文件追加数据的性能很难被超越,因为这是一种最简单的写入操作。任何类型的索引通常会减慢写入速度,因为每次写入数据时,索引也需要更新。
这是存储系统中的一个重要权衡:精心选择的索引可以加快读取查询,但每个索引都会消耗额外的磁盘空间并减慢写入速度,有时会显著减慢1。因此,数据库通常不会默认索引所有内容,而是要求您——编写应用程序或管理数据库的人——手动选择索引,利用您对应用程序典型查询模式的了解。然后,您可以选择那些为您的应用程序带来最大收益的索引,而不会在写入时引入不必要的额外开销。
日志结构存储
首先,假设您希望继续在 db_set 写入的仅追加文件中存储数据,并且您只想加快读取速度。您可以通过在内存中保持一个哈希映射来实现这一点,其中每个键映射到文件中该键的最新值可以找到的字节偏移量,如图 4-1 所示。

每当您向文件中追加一个新的键值对时,您还会更新哈希映射,以反映您刚写入的数据的偏移量。当您想查找一个值时,您使用哈希映射找到日志文件中的偏移量,寻址到该位置并读取值。如果数据文件的那部分已经在文件系统缓存中,则读取根本不需要任何磁盘 I/O。
这种方法要快得多,但仍然存在几个问题:
您从未释放被旧日志条目占用的磁盘空间;如果您继续向数据库写入数据,可能会耗尽磁盘空间。
哈希映射不会被持久化,因此在重新启动数据库时必须重建它——例如,通过扫描整个日志文件来查找每个键的最新字节偏移量。如果数据量很大,这会使重启变得缓慢。
哈希表必须适合内存。原则上,您可以在磁盘上维护一个哈希表,但不幸的是,使磁盘上的哈希映射表现良好是困难的。这需要大量的随机访问 I/O,当它变满时扩展成本高,并且哈希冲突需要复杂的逻辑2。
范围查询效率不高。例如,您无法轻松扫描所有介于 10000 和 19999 之间的键——您必须在哈希映射中逐个查找每个键。
SSTable 文件格式
在实际应用中,哈希表并不常用于数据库索引,而是更常见的是将数据保存在按键排序的结构中3。这种结构的一个例子是有序字符串表,简称 SSTable,如图 4-2 所示。该文件格式同样存储键值对,但确保它们按键排序,并且每个键在文件中只出现一次。
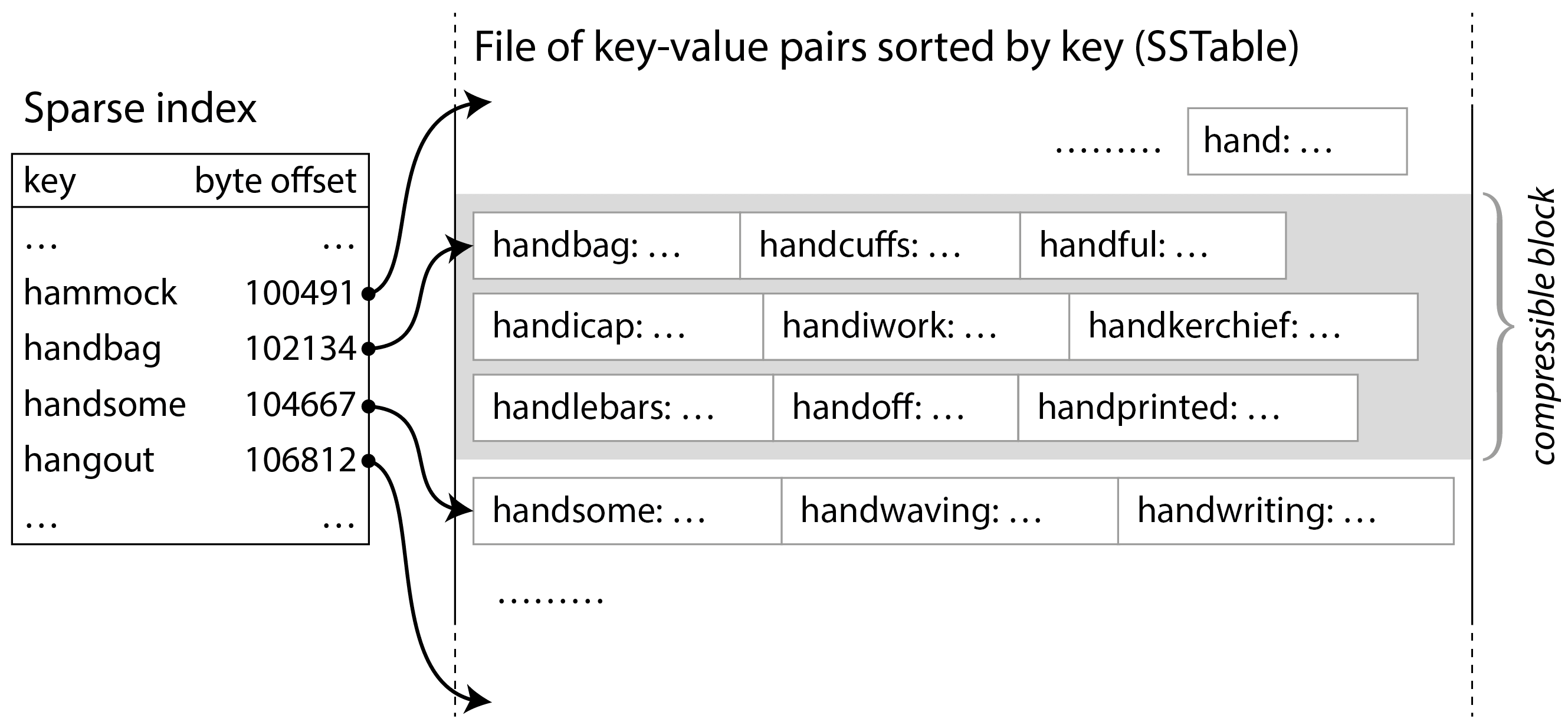
现在您不需要将所有键都保存在内存中:您可以将 SSTable 中的键值对分组为几个千字节的块,然后将每个块的第一个键存储在索引中。这种只存储部分键的索引称为稀疏索引。该索引存储在 SSTable 的一个单独部分,例如使用不可变 B 树、字典树或其他允许快速查找特定键的数据结构4。
例如,在图 4-2 中,一个块的第一个键是 handbag ,下一个块的第一个键是 handsome 。现在假设你在寻找键 handiwork ,它并没有出现在稀疏索引中。由于排序,你知道 handiwork 必须出现在 handbag 和 handsome 之间。这意味着你可以寻址到 handbag 的偏移量,并从那里扫描文件,直到找到 handiwork (如果该键不在文件中,则可能找不到)。几千字节的块可以非常快速地扫描。
此外,每个记录块都可以被压缩(如图 4-2 中的阴影区域所示)。除了节省磁盘空间,压缩还减少了 I/O 带宽的使用,但代价是需要使用更多的 CPU 时间。
构建和合并 SSTables
SSTable 文件格式比仅追加日志更适合读取,但它使写入变得更加困难。我们不能简单地在末尾追加,因为那样文件将不再是排序的(除非键恰好以升序写入)。如果每次在中间插入一个键时都必须重写整个 SSTable,写入的成本将变得非常高。
我们可以通过一种日志结构化的方法来解决这个问题,这是一种追加日志和排序文件的混合体:
当写入请求到来时,将其添加到一个内存中的有序映射数据结构中,例如红黑树、跳表5 或字典树6。使用这些数据结构,您可以以任意顺序插入键,高效查找它们,并按排序顺序读取它们。这个内存数据结构称为 memtable。
当 memtable 的大小超过某个阈值——通常是几兆字节——时,将其以排序顺序写入磁盘,形成一个 SSTable 文件。我们将这个新的 SSTable 文件称为数据库的最新段,它作为一个单独的文件与旧段一起存储。每个段都有其内容的单独索引。在新的段被写入磁盘时,数据库可以继续写入一个新的 memtable 实例,而当 SSTable 的写入完成时,旧 memtable 的内存会被释放。
为了读取某个键的值,首先尝试在内存表和最新的磁盘段中查找该键。如果没有找到,则查看下一个较旧的段,依此类推,直到找到该键或到达最旧的段。如果在任何段中都没有找到该键,则表示它在数据库中不存在。
不时在后台运行合并和压缩过程,以组合段文件并丢弃被覆盖或删除的值。
合并段的工作原理类似于归并排序算法5。该过程如图 4-3 所示:开始并排读取输入文件,查看每个文件中的第一个键,将最低的键(根据排序顺序)复制到输出文件中,然后重复。如果同一个键出现在多个输入文件中,则只保留较新的值。这会生成一个新的合并段文件,同样按键排序,每个键只有一个值,并且它使用最少的内存,因为我们可以一次遍历一个键的 SSTable。
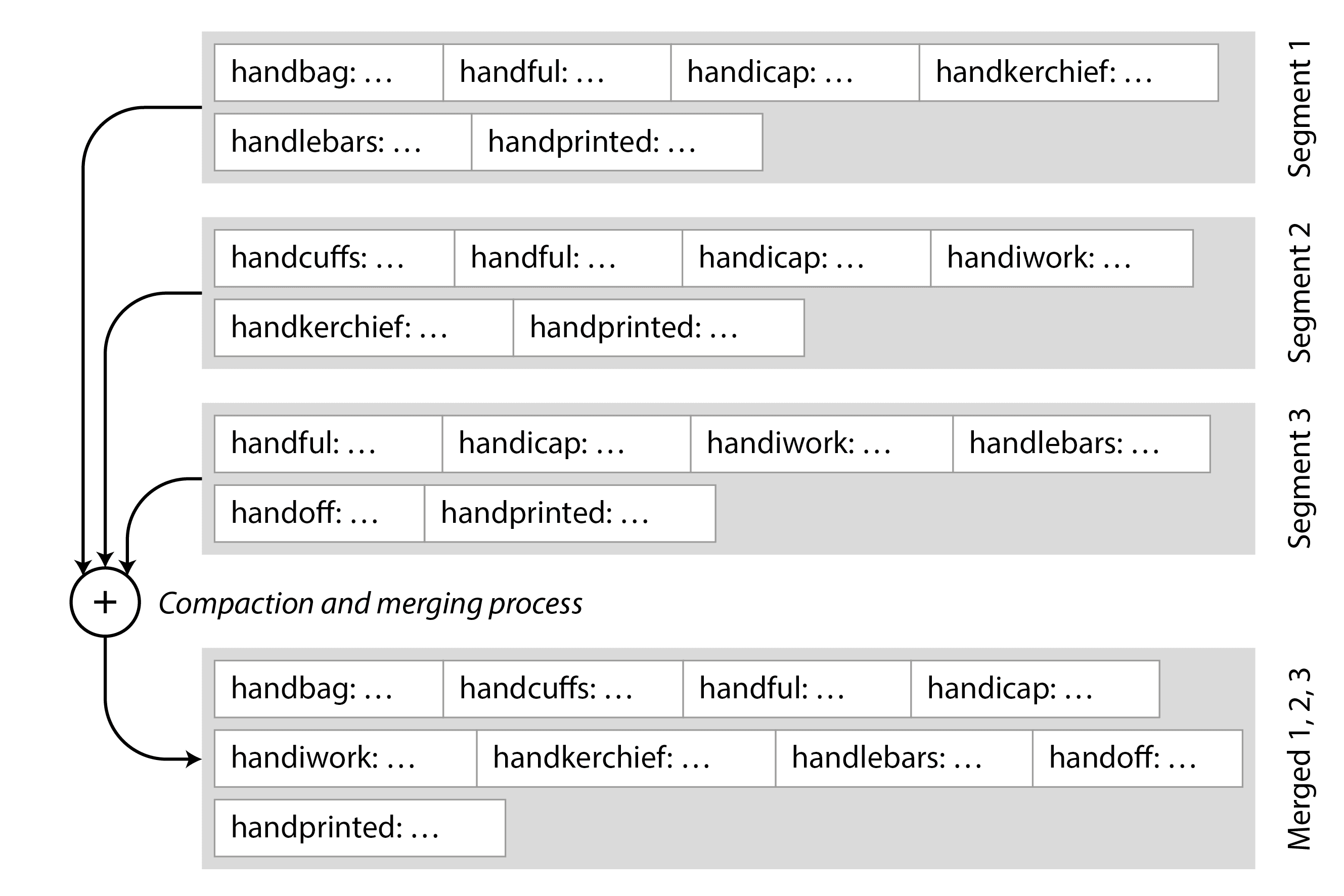
为了确保在数据库崩溃时内存表中的数据不会丢失,存储引擎在磁盘上保留一个单独的日志,所有写入操作都会立即附加到该日志中。这个日志并不是按键排序的,但这并不重要,因为它的唯一目的是在崩溃后恢复内存表。每当内存表被写入到 SSTable 时,日志中相应的部分可以被丢弃。
如果您想删除一个键及其相关值,您必须将一个称为墓碑的特殊删除记录附加到数据文件中。当日志段被合并时,墓碑会告诉合并过程丢弃被删除键的任何先前值。一旦墓碑被合并到最旧的段中,它就可以被丢弃。
这里描述的算法本质上是 RocksDB7、Cassandra、Scylla 和 HBase8中使用的算法,所有这些都受到谷歌的 Bigtable 论文9(引入了 SSTable 和内存表术语)的启发。
该算法最初于 1996 年以日志结构合并树(Log-Structured Merge-Tree 或 LSM-Tree)10的名称发布,基于早期对日志结构文件系统的研究11。因此,基于合并和压缩排序文件原理的存储引擎通常被称为 LSM 存储引擎。
在 LSM 存储引擎中,段文件是在一次写入中生成的(要么通过写出内存表,要么通过合并一些现有段),此后它是不可变的。段的合并和压缩可以在后台线程中进行,在此过程中,我们仍然可以继续使用旧的段文件提供读取服务。当合并过程完成后,我们将读取请求切换到使用新的合并段,而不是旧的段,然后可以删除旧的段文件。
段文件不一定必须存储在本地磁盘上:它们也非常适合写入对象存储。例如,SlateDB 和 Delta Lake12采用了这种方法。
拥有不可变的段文件也简化了崩溃恢复:如果在写出内存表或合并段时发生崩溃,数据库可以简单地删除未完成的 SSTable 并重新开始。持久化写入内存表的日志可能包含不完整的记录,如果在写入记录的过程中发生崩溃,或者如果磁盘已满;这些通常通过在日志中包含校验和来检测,并丢弃损坏或不完整的日志条目。我们将在第 8 章中详细讨论持久性和崩溃恢复。
布隆过滤器
在 LSM 存储中,读取很久以前最后更新的键或不存在的键可能会很慢,因为存储引擎需要检查多个段文件。为了加快这种读取速度,LSM 存储引擎通常在每个段中包含一个布隆过滤器13,它提供了一种快速但近似的方法来检查特定键是否出现在特定的 SSTable 中。
图 4-4 展示了一个包含两个键和 16 位的布隆过滤器示例(实际上,它会包含更多的键和更多的位)。对于 SSTable 中的每个键,我们计算一个哈希函数,生成一组数字,然后将这些数字解释为位数组的索引14。我们将对应于这些索引的位设置为 1,其余的位保持为 0。例如,键 handbag 哈希到数字(2, 9, 4),因此我们将第 2 位、第 9 位和第 4 位设置为 1。位图随后作为 SSTable 的一部分存储,连同稀疏键索引。这会占用一些额外的空间,但与 SSTable 的其余部分相比,布隆过滤器通常是小的。
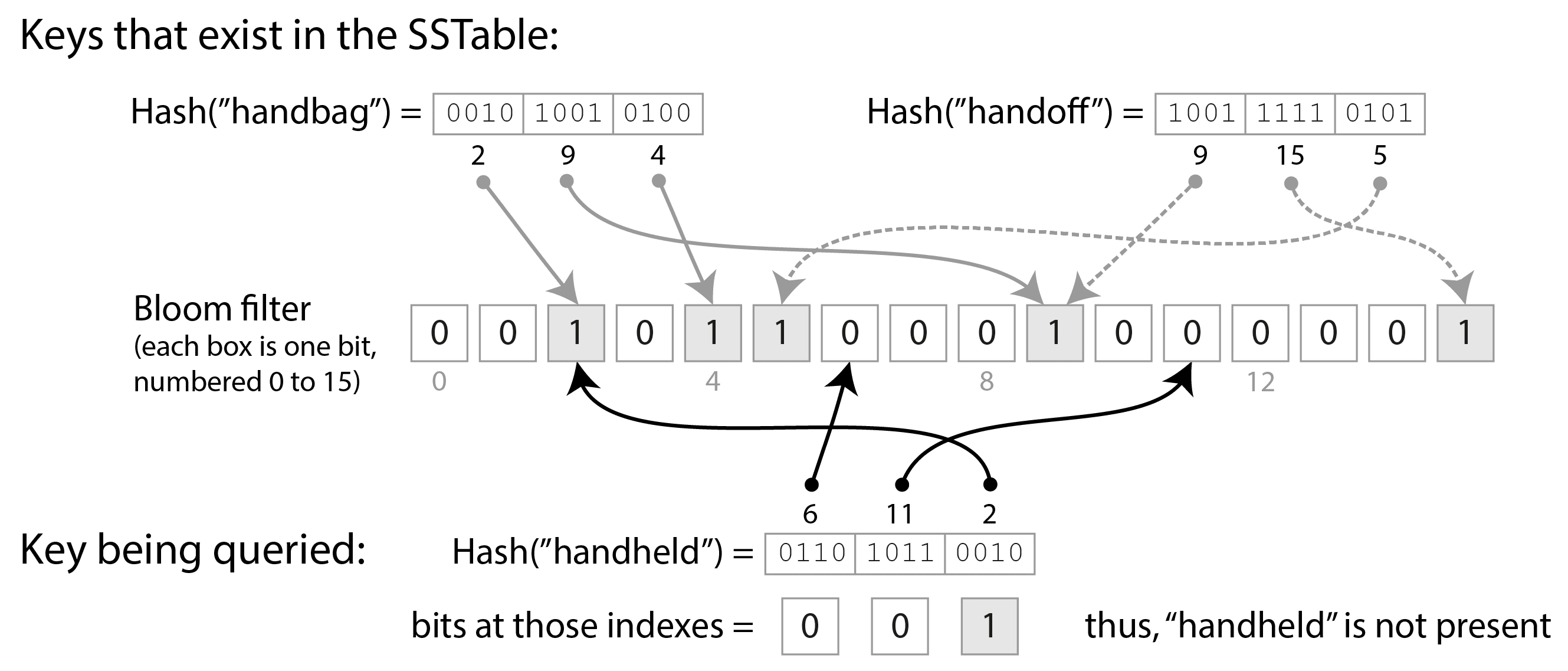
当我们想知道一个键是否出现在 SSTable 中时,我们计算该键的相同哈希值,并检查这些索引处的位。例如,在图 4-4 中,我们查询键 handheld ,它哈希到(6, 11, 2)。其中一个位是 1(即,第 2 位),而另外两个是 0。这些检查可以通过所有 CPU 支持的位运算非常快速地完成。
如果至少有一个位是 0,我们知道该键肯定不出现在 SSTable 中。如果查询中的所有位都是 1,那么该键很可能在 SSTable 中,但也有可能是由于巧合,所有这些位都被其他键设置为 1。这种看似存在键但实际上并不存在的情况称为假阳性。
假阳性的概率取决于键的数量、每个键设置的位数以及布隆过滤器中的总位数。您可以使用在线计算工具来计算适合您应用程序的正确参数15。作为经验法则,您需要为 SSTable 中的每个键分配 10 个位的布隆过滤器空间,以获得 1%的假阳性概率,并且每增加 5 个位的分配,概率将减少十倍。
在 LSM 存储引擎的上下文中,假阳性并不是问题:
如果布隆过滤器表示某个键不存在,我们可以安全地跳过该 SSTable,因为我们可以确定它不包含该键。
如果布隆过滤器表示该键存在,我们必须查阅稀疏索引并解码键值对块,以检查该键是否真的存在。如果这是一个假阳性,我们做了一些不必要的工作,但否则没有造成任何损害——我们只需继续搜索下一个较旧的段。
压缩策略
一个重要的细节是 LSM 存储如何选择何时执行压缩,以及选择哪些 SSTable 进行压缩。许多基于 LSM 的存储系统允许您配置使用哪种压缩策略,一些常见的选择是16:
大小分层压缩
较新且较小的 SSTables 会逐步合并到较旧且较大的 SSTables 中。包含较旧数据的 SSTables 可能会变得非常大,合并它们需要大量的临时磁盘空间。这种策略的优点在于它可以处理非常高的写入吞吐量。
分层压缩
键范围被拆分成较小的 SSTables,较旧的数据被移动到单独的“层级”中,这使得压缩可以更增量地进行,并且使用的磁盘空间比大小分层策略少。这种策略在读取时比大小分层压缩更有效,因为存储引擎需要读取的 SSTables 更少,以检查它们是否包含该键。
作为经验法则,如果你的操作主要是写入且读取较少,则大小分层压缩表现更好;而如果你的工作负载以读取为主,则分层压缩表现更好。如果你频繁写入少量键而很少写入大量键,那么分层压缩也可能是有利的17。
尽管有许多细微之处,LSM 树的基本思想——保持一系列在后台合并的 SSTable——是简单而有效的。我们在“比较 B 树和 LSM 树”中更详细地讨论它们的性能特征。
嵌入式存储引擎
许多数据库作为服务运行,通过网络接受查询,但也有一些嵌入式数据库不暴露网络 API。相反,它们是与您的应用程序代码在同一进程中运行的库,通常在本地磁盘上读取和写入文件,您通过正常的函数调用与它们进行交互。嵌入式存储引擎的例子包括 RocksDB、SQLite、LMDB、DuckDB 和 KùzuDB18。
嵌入式数据库在移动应用中非常常见,用于存储本地用户的数据。在后端,如果数据足够小以适合单台机器,并且并发事务不多,它们可以是一个合适的选择。例如,在一个多租户系统中,如果每个租户都足够小且与其他租户完全独立(即,您不需要运行结合多个租户数据的查询),您可以为每个租户使用一个单独的嵌入式数据库实例19。
我们在本章讨论的存储和检索方法同时适用于嵌入式数据库和客户端-服务器数据库。在第 6 章和第 7 章中,我们将讨论在多台机器上扩展数据库的技术。
B 树
日志结构的方法很受欢迎,但这并不是唯一的键值存储形式。用于按键读取和写入数据库记录的最广泛使用的结构是 B 树。
1970 年引入20,不到 10 年后被称为“无处不在”21,B 树经受住了时间的考验。它们仍然是几乎所有关系数据库中的标准索引实现,许多非关系数据库也使用它们。
与 SSTables 类似,B 树按键对键值对进行排序,这允许高效的键值查找和范围查询。但相似之处到此为止:B 树有着非常不同的设计理念。
我们之前看到的日志结构索引将数据库分解为可变大小的段,通常大小为几兆字节或更多,这些段被写入一次后便不可更改。相比之下,B 树将数据库分解为固定大小的块或页面,并可以就地覆盖页面。传统上,一个页面的大小为 4 KiB,但 PostgreSQL 现在默认使用 8 KiB,而 MySQL 默认使用 16 KiB。
每个页面可以通过页面编号来识别,这使得一个页面可以引用另一个页面——类似于指针,但在磁盘上而不是在内存中。如果所有页面都存储在同一个文件中,将页面编号乘以页面大小可以得到页面在文件中的字节偏移量。我们可以使用这些页面引用来构建页面树,如图 4-5 所示。
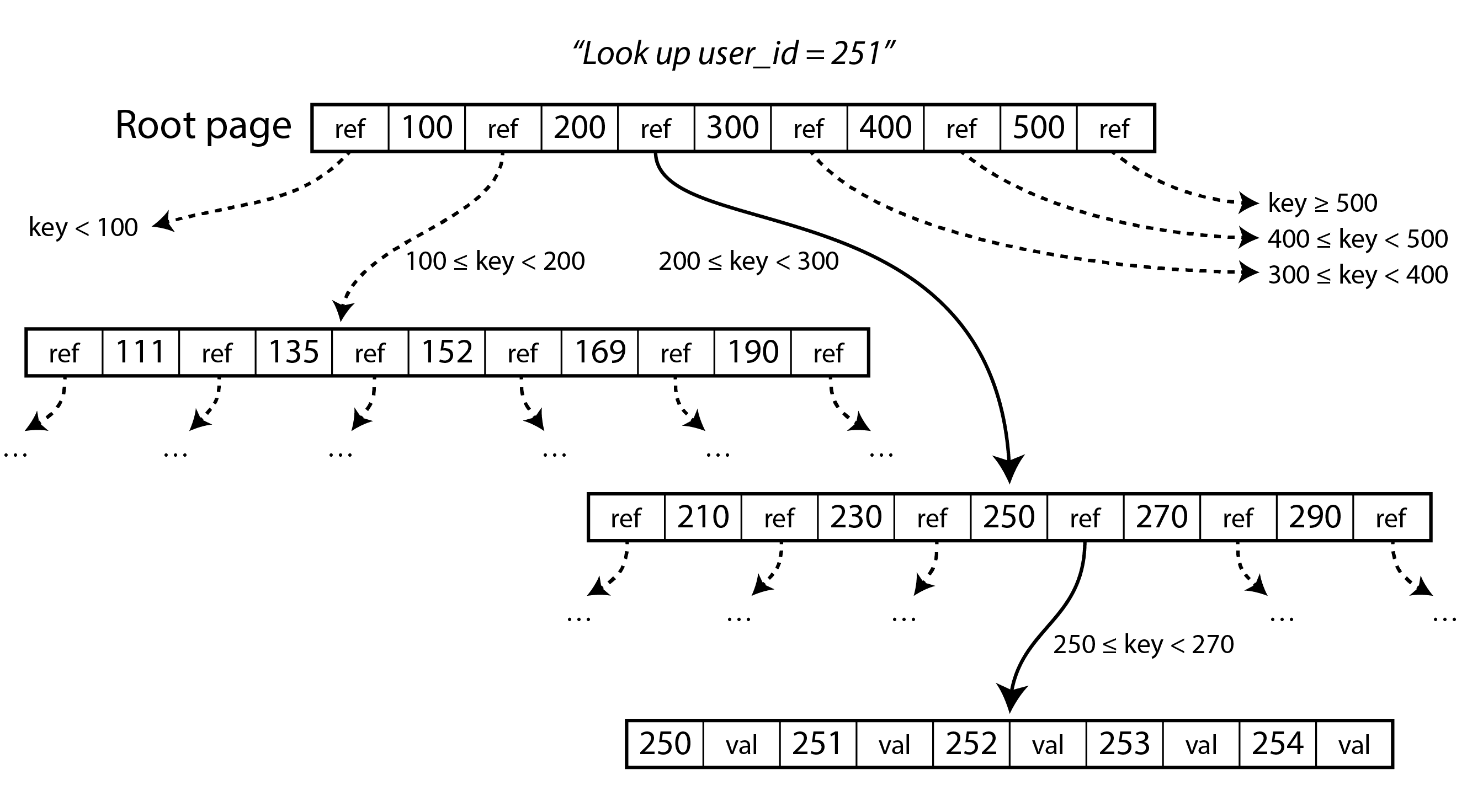
一个页面被指定为 B 树的根;每当你想在索引中查找一个键时,你从这里开始。该页面包含几个键和对子页面的引用。每个子页面负责一系列连续的键,而引用之间的键指示这些范围之间的边界在哪里。(这种结构有时被称为 B + 树,但我们不需要将其与其他 B 树变体区分开。)
在图 4-5 的示例中,我们正在寻找键 251,因此我们知道需要在 200 和 300 的边界之间跟踪页面引用。这将我们带到一个类似的页面,该页面进一步将 200–300 范围细分为子范围。最终,我们到达一个包含单个键的页面(叶子页面),该页面要么在线包含每个键的值,要么包含指向可以找到值的页面的引用。
B 树中一个页面对子页面的引用数量称为分支因子。例如,在图 4-5 中,分支因子为六。在实际应用中,分支因子取决于存储页面引用和范围边界所需的空间量,但通常为几百。
如果您想更新 B 树中现有键的值,您需要搜索包含该键的叶子页,并用包含新值的版本覆盖磁盘上的该页。如果您想添加一个新键,您需要找到范围包含新键的页面,并将其添加到该页面。如果页面中没有足够的空闲空间来容纳新键,则该页面将被拆分为两个半满的页面,并且父页面将被更新以反映键范围的新细分。
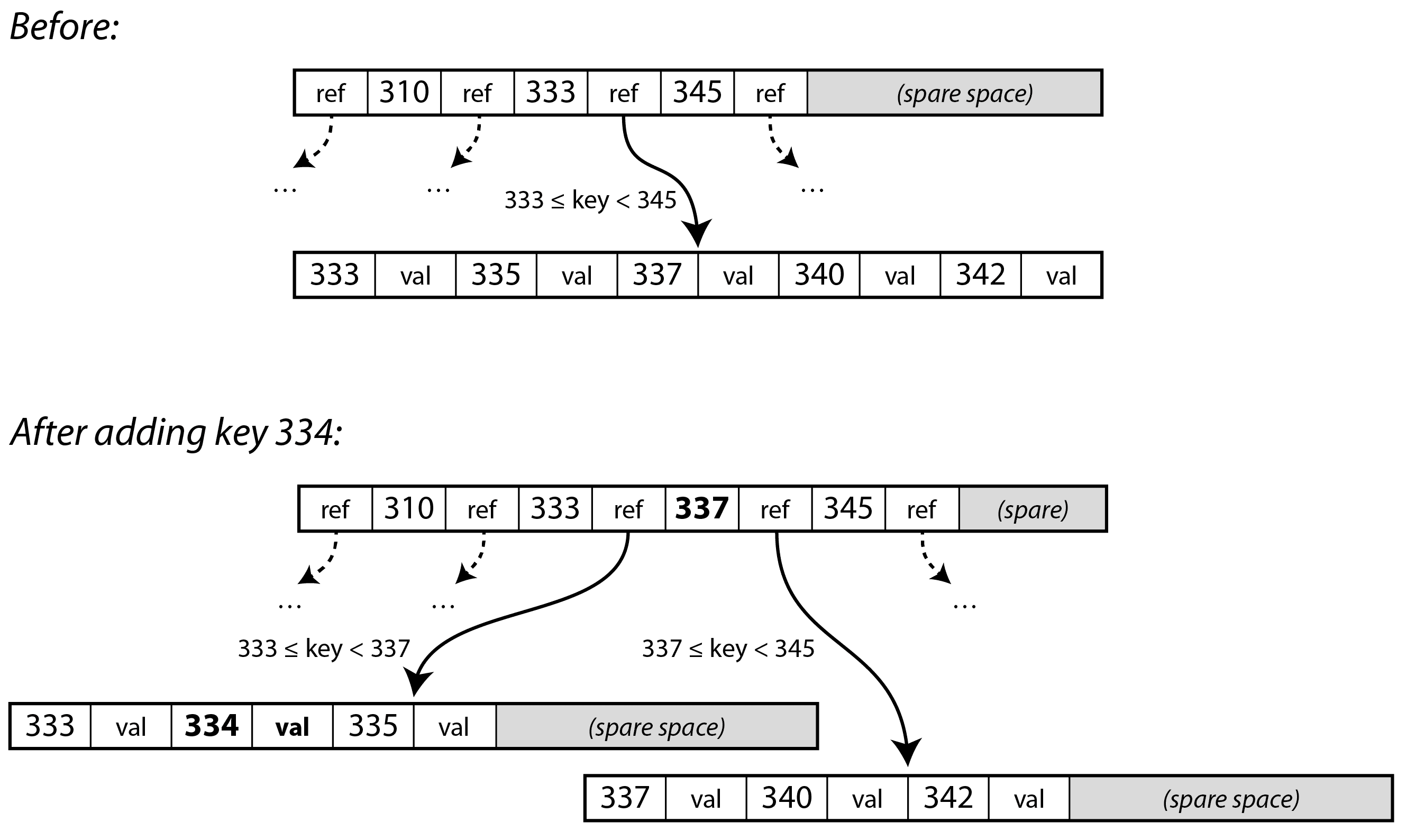
在图 4-6 的例子中,我们想要插入键 334,但范围为 333–345 的页面已经满了。因此,我们将其拆分为一个范围为 333–337(包括新键)的页面和一个范围为 337–344 的页面。我们还必须更新父页面,以便对两个子页面都有引用,并在它们之间设置边界值 337。如果父页面没有足够的空间来容纳新的引用,它也可能需要被拆分,而拆分可以一直延续到树的根部。当根被拆分时,我们在其上方创建一个新的根。删除键(这可能需要合并节点)更为复杂5。
该算法确保树保持平衡:具有 n 个键的 B 树的深度始终为 O(log n)。大多数数据库可以适应深度为三到四层的 B 树,因此您不需要跟踪许多页面引用就能找到所需的页面。(一个具有 500 的分支因子的 4 KiB 页面的四层树可以存储多达 250 TB。)
使 B 树可靠
B 树的基本写入操作是用新数据覆盖磁盘上的一个页面。假设覆盖操作不会改变页面的位置;也就是说,当页面被覆盖时,所有指向该页面的引用保持不变。这与日志结构索引(如 LSM 树)形成鲜明对比,后者只是在文件末尾追加数据(并最终删除过时的文件),但从不就地修改文件。
一次覆盖多个页面,例如在页面分裂时,是一个危险的操作:如果数据库在只有部分页面被写入后崩溃,最终会导致树结构损坏(例如,可能会出现一个孤立页面,它不是任何父页面的子页面)。
为了使数据库在崩溃时具有恢复能力,B 树实现通常会在磁盘上包含一个额外的数据结构:预写日志(WAL)。这是一个仅追加的文件,所有 B 树的修改必须在应用到树的页面之前写入该文件。当数据库在崩溃后重新启动时,这个日志用于将 B 树恢复到一致状态。在文件系统中,相应的机制被称为日志记录。
为了提高性能,B 树的实现通常不会立即将每个修改过的页面写入磁盘,而是先在内存中缓冲 B 树页面一段时间。写前日志(WAL)还确保在发生崩溃的情况下数据不会丢失:只要数据已写入 WAL,并通过 fsync() 系统调用刷新到磁盘,数据就会持久化,因为数据库能够在崩溃后恢复它22。
B 树变体
由于 B 树已经存在了很长时间,多年来开发了许多变体。仅举几例:
-
一些数据库(如 LMDB)采用写时复制方案,而不是覆盖页面并维护用于崩溃恢复的 WAL。修改后的页面被写入不同的位置,并在树中创建父页面的新版本,指向新位置。这种方法对于并发控制也很有用,正如我们将在“快照隔离和可重复读”中看到的那样。
-
我们可以通过不存储整个键,而是对其进行缩写来节省页面空间。特别是在树的内部页面中,键只需要提供足够的信息以作为键范围之间的边界。将更多的键打包到一个页面中可以使树具有更高的分支因子,从而减少层数。
-
为了加快对按顺序排列的键范围的扫描,一些 B 树实现尝试将树布局为叶页面在磁盘上按顺序出现,从而减少磁盘寻址的次数。然而,随着树的增长,保持这种顺序是困难的。
-
树中添加了额外的指针。例如,每个叶页面可能会有对其左右兄弟页面的引用,这样可以按顺序扫描键,而无需跳回父页面。
比较 B 树和 LSM 树
作为经验法则,LSM 树更适合写密集型应用,而 B 树在读取时更快2324。然而,基准测试通常对工作负载的细节非常敏感。您需要使用特定的工作负载测试系统,以便进行有效的比较。此外,LSM 和 B 树之间并不是严格的二选一选择:存储引擎有时会融合两种方法的特性,例如通过拥有多个 B 树并以 LSM 风格合并它们。在本节中,我们将简要讨论在测量存储引擎性能时值得考虑的一些事项。
读取性能
在 B 树中,查找一个键涉及在 B 树的每一层读取一个页面。由于层数通常相对较少,这意味着从 B 树读取通常很快且性能可预测。在 LSM 存储引擎中,读取通常需要检查在不同压缩阶段的多个 SSTable,但布隆过滤器有助于减少所需的实际磁盘 I/O 操作次数。这两种方法都可以表现良好,哪种更快取决于存储引擎和工作负载的细节。
范围查询在 B 树上简单且快速,因为它们可以利用树的排序结构。在 LSM 存储上,范围查询也可以利用 SSTable 的排序,但它们需要并行扫描所有段并合并结果。布隆过滤器对范围查询没有帮助(因为你需要计算范围内每个可能键的哈希,这在实际操作中是不可行的),这使得在 LSM 方法中,范围查询的成本高于点查询25。
如果内存表填满,高写入吞吐量可能会导致日志结构存储引擎的延迟峰值。这种情况发生在数据无法快速写入磁盘时,可能是因为压缩过程无法跟上传入的写入。许多存储引擎,包括 RocksDB,在这种情况下会执行背压:它们会暂停所有读取和写入,直到内存表被写入磁盘2627。
关于读取吞吐量,现代 SSD(尤其是 NVMe)可以并行执行许多独立的读取请求。LSM 树和 B 树都能够提供高读取吞吐量,但存储引擎需要经过精心设计,以利用这种并行性28。
顺序写入与随机写入
使用 B 树时,如果应用程序写入的键分散在整个键空间中,产生的磁盘操作也会随机分散,因为存储引擎需要覆盖的页面可能位于磁盘的任何位置。另一方面,日志结构存储引擎一次写入整个段文件(要么写出内存表,要么在压缩现有段时),这些段文件比 B 树中的页面要大得多。
许多小的、分散的写入模式(如在 B 树中发现的)称为随机写入,而较少的大写入模式(如在 LSM 树中发现的)称为顺序写入。磁盘通常具有比随机写入更高的顺序写入吞吐量,这意味着日志结构存储引擎通常可以在相同硬件上处理比 B 树更高的写入吞吐量。这种差异在旋转磁盘硬盘(HDD)上尤其明显;在大多数数据库今天使用的固态硬盘(SSD)上,差异较小,但仍然显著(见“SSD 上的顺序写入与随机写入”)。
SSD 上的顺序写入与随机写入 在旋转磁盘硬盘(HDD)上,顺序写入的速度远快于随机写入:随机写入必须机械地将磁头移动到新位置,并等待盘片的正确部分经过磁头下方,这需要几毫秒——在计算机的时间尺度上,这是一段漫长的时间。然而,固态硬盘(SSD),包括 NVMe(非易失性内存快速通道,即连接到 PCI Express 总线的闪存),在许多使用案例中已经超越了 HDD,并且不受此类机械限制。
然而,SSD 在顺序写入方面的吞吐量也高于随机写入。原因在于闪存可以一次读取或写入一页(通常为 4 KiB),但只能一次擦除一个块(通常为 512 KiB)。一个块中的某些页面可能包含有效数据,而其他页面可能包含不再需要的数据。在擦除一个块之前,控制器必须首先将包含有效数据的页面移动到其他块中;这个过程称为垃圾回收(GC)29。
顺序写入工作负载一次写入较大的数据块,因此一个完整的 512 KiB 块很可能属于单个文件;当该文件随后被删除时,整个块可以被擦除,而无需执行任何垃圾回收(GC)。另一方面,对于随机写入工作负载,一个块更可能包含有效和无效数据的混合,因此在块被擦除之前,GC 需要执行更多的工作303132。
GC 消耗的写入带宽因此无法用于应用程序。此外,GC 执行的额外写入会加速闪存的磨损;因此,随机写入比顺序写入更快地磨损驱动器。
写放大
无论何种类型的存储引擎,来自应用程序的一个写请求都会转化为对底层磁盘的多个 I/O 操作。使用 LSM 树时,值首先被写入日志以确保持久性,然后在 memtable 写入磁盘时再次写入,每当键值对参与压缩时也会再次写入。(如果值的大小明显大于键,可以通过将值与键分开存储,并仅对包含键和对值的引用的 SSTables 进行压缩,从而减少这种开销33。)
B 树索引必须至少写入每一条数据两次:一次写入预写日志,一次写入树页面本身。此外,即使该页面中只有几个字节发生了变化,它们有时也需要写出整个页面,以确保在崩溃或电源故障后 B 树能够正确恢复3435。
如果你将某个工作负载中写入磁盘的总字节数除以如果你仅仅写入一个没有索引的追加日志所需写入的字节数,你就得到了写入放大率。(有时写入放大率是以 I/O 操作而不是字节来定义的。)在写入密集型应用中,瓶颈可能是数据库写入磁盘的速率。在这种情况下,写入放大率越高,它在可用磁盘带宽内能够处理的每秒写入次数就越少。
写入放大率在 LSM 树和 B 树中都是一个问题。哪种更好取决于各种因素,例如你的键和值的长度,以及你覆盖现有键与插入新键的频率。对于典型的工作负载,LSM 树往往具有较低的写入放大率,因为它们不需要写入整个页面,并且可以压缩 SSTable 的块36。这也是使 LSM 存储引擎非常适合写入密集型工作负载的另一个因素。
除了影响吞吐量,写入放大率还与 SSD 的磨损相关:具有较低写入放大率的存储引擎将使 SSD 磨损得更慢。
在测量存储引擎的写入吞吐量时,重要的是要进行足够长时间的实验,以便写放大效应变得明显。当写入一个空的 LSM 树时,还没有进行合并,因此所有的磁盘带宽都可用于新的写入。随着数据库的增长,新的写入需要与合并共享磁盘带宽。
磁盘空间使用
B 树可能会随着时间的推移而变得碎片化:例如,如果大量键被删除,数据库文件可能会包含许多不再被 B 树使用的页面。后续对 B 树的添加可以使用这些空闲页面,但由于它们位于文件中间,因此无法轻易返回给操作系统,因此它们仍然占用文件系统的空间。因此,数据库需要一个后台进程来移动页面,以便更好地放置它们,例如 PostgreSQL 中的清理进程22。
在 LSM 树中,碎片化问题较小,因为压缩过程会定期重写数据文件,而且 SSTable 没有带有未使用空间的页面。此外,键值对块在 SSTable 中可以更好地压缩,因此通常在磁盘上产生比 B 树更小的文件。被覆盖的键和值在被压缩移除之前会继续占用空间,但在使用分层压缩时,这种开销相当低3637。大小分层压缩(见“压缩策略”)在压缩期间会使用更多的磁盘空间,尤其是暂时。
在磁盘上拥有某些数据的多个副本在需要删除某些数据时也可能成为问题,并且需要确保这些数据确实已被删除(可能是为了遵守数据保护法规)。例如,在大多数 LSM 存储引擎中,已删除的记录可能仍然存在于更高的层级,直到表示删除的墓碑在所有压缩层级中传播,这可能需要很长时间。专业的存储引擎设计可以更快地传播删除操作38。
另一方面,SSTable 段文件的不可变特性在你想要在某个时间点对数据库进行快照时非常有用(例如,用于备份或创建数据库的测试副本):你可以将内存表写出,并记录在那个时间点存在的段文件。只要你不删除快照中包含的文件,就不需要实际复制它们。在一个页面被覆盖的 B 树中,高效地进行这样的快照则更加困难。
多列和二级索引
到目前为止,我们只讨论了键值索引,这类似于关系模型中的主键索引。主键唯一标识关系表中的一行,或文档数据库中的一个文档,或图数据库中的一个顶点。数据库中的其他记录可以通过其主键(或 ID)引用该行/文档/顶点,索引用于解析这些引用。
二级索引也是非常常见的。在关系数据库中,您可以使用 CREATE INDEX 命令在同一表上创建多个二级索引,从而允许您按主键以外的列进行搜索。例如,在第 3 章的图 3-1 中,您很可能会在 user_id 列上有一个二级索引,以便您可以找到每个表中属于同一用户的所有行。
二级索引可以很容易地从键值索引构建。主要区别在于,在二级索引中,索引的值不一定是唯一的;也就是说,可能在同一个索引条目下有多行(文档、顶点)。这可以通过两种方式解决:要么使索引中的每个值成为匹配行标识符的列表(类似于全文索引中的发布列表),要么通过附加行标识符使每个条目唯一。具有就地更新功能的存储引擎,如 B 树和日志结构存储,都可以用于实现索引。
在索引中存储值
索引中的键是查询搜索的对象,但值可以是几种不同的东西:
-
如果实际数据(行、文档、顶点)直接存储在索引结构中,则称为聚集索引。例如,在 MySQL 的 InnoDB 存储引擎中,表的主键始终是聚集索引,而在 SQL Server 中,您可以为每个表指定一个聚集索引。
-
另外,值可以是对实际数据的引用:要么是相关行的主键(InnoDB 为二级索引执行此操作),要么是对磁盘上位置的直接引用。在后一种情况下,存储行的地方称为堆文件,它以无特定顺序存储数据(它可能是仅追加的,或者可能跟踪已删除的行以便稍后用新数据覆盖它们)。例如,Postgres 使用堆文件方法39。
-
两者之间的折中方案是覆盖索引或包含列的索引,它在索引中存储了表的一些列,此外还在堆或主键聚集索引中存储完整的行40。这使得某些查询可以仅通过使用索引来回答,而无需解析主键或查找堆文件(在这种情况下,索引被称为覆盖查询)。这可以使某些查询更快,但数据的重复意味着索引占用更多的磁盘空间,并且会减慢写入速度。
到目前为止讨论的索引仅将单个键映射到一个值。如果您需要同时查询表的多个列(或文档中的多个字段),请参见“多维和全文索引”。
在不更改键的情况下更新值时,堆文件方法可以允许记录就地覆盖,前提是新值不大于旧值。如果新值更大,情况就更复杂,因为它可能需要移动到堆中的新位置,以便有足够的空间。在这种情况下,要么需要更新所有索引以指向记录的新堆位置,要么在旧堆位置留下一个转发指针2。
将所有内容保留在内存中
本章讨论的数据结构都是对磁盘限制的回应。与主内存相比,磁盘的处理相对麻烦。无论是磁盘还是 SSD,如果希望在读写时获得良好的性能,磁盘上的数据都需要仔细布局。然而,我们容忍这种麻烦,因为磁盘有两个显著的优势:它们是耐用的(如果断电,其内容不会丢失),并且每千兆字节的成本低于 RAM。
随着 RAM 变得更加便宜,每千兆字节的成本论点逐渐减弱。许多数据集实际上并没有那么大,因此将它们完全保存在内存中是相当可行的,可能分布在几台机器上。这导致了内存数据库的发展。
一些内存键值存储,如 Memcached,仅用于缓存用途,在机器重启时数据丢失是可以接受的。但其他内存数据库则旨在实现持久性,这可以通过特殊硬件(如电池供电的 RAM)、将更改日志写入磁盘、定期将快照写入磁盘或将内存状态复制到其他机器来实现。
当内存数据库重启时,它需要从磁盘或通过网络从副本重新加载其状态(除非使用了特殊硬件)。尽管写入磁盘,它仍然是一个内存数据库,因为磁盘仅用作持久性的追加日志,读取完全来自内存。写入磁盘也具有操作上的优势:磁盘上的文件可以轻松备份、检查和由外部工具分析。
像 VoltDB、SingleStore 和 Oracle TimesTen 这样的产品是具有关系模型的内存数据库,供应商声称通过消除与管理磁盘数据结构相关的所有开销,它们可以提供显著的性能提升4142。RAMCloud 是一个开源的内存键值存储,具有持久性(使用日志结构的方法来处理内存中的数据以及磁盘上的数据)43。Redis 和 Couchbase 通过异步写入磁盘提供弱持久性。
与直觉相反,内存数据库的性能优势并不是因为它们不需要从磁盘读取数据。即使是基于磁盘的存储引擎,如果内存足够,也可能永远不需要从磁盘读取,因为操作系统会将最近使用的磁盘块缓存到内存中。相反,它们之所以可以更快,是因为可以避免将内存数据结构编码为可以写入磁盘的形式所带来的开销44。
除了性能,内存数据库的另一个有趣领域是提供难以通过基于磁盘的索引实现的数据模型。例如,Redis 提供了一个类似数据库的接口,可以用于各种数据结构,如优先队列和集合。由于它将所有数据保存在内存中,因此其实现相对简单。
分析数据存储
数据仓库的数据模型通常是关系型的,因为 SQL 通常非常适合分析查询。有许多图形数据分析工具可以生成 SQL 查询,可视化结果,并允许分析师通过下钻、切片和切块等操作探索数据。
表面上看,数据仓库和关系型 OLTP 数据库看起来相似,因为它们都有 SQL 查询接口。然而,这些系统的内部结构可能看起来非常不同,因为它们针对非常不同的查询模式进行了优化。许多数据库供应商现在专注于支持事务处理或分析工作负载,但不是两者兼顾。
一些数据库,如 Microsoft SQL Server、SAP HANA 和 SingleStore,支持在同一产品中进行事务处理和数据仓库。然而,这些混合事务和分析处理(HTAP)数据库(在“数据仓库”中介绍)正日益成为两个独立的存储和查询引擎,这些引擎恰好可以通过一个共同的 SQL 接口访问45464748。
云数据仓库
数据仓库供应商如 Teradata、Vertica 和 SAP HANA 在商业许可证下销售本地仓库和基于云的解决方案。但随着许多客户转向云,新兴的云数据仓库如 Google Cloud BigQuery、Amazon Redshift 和 Snowflake 也得到了广泛采用。与传统数据仓库不同,云数据仓库利用可扩展的云基础设施,如对象存储和无服务器计算平台。
云数据仓库往往与其他云服务的集成更好,并且更具弹性。例如,许多云仓库支持自动日志摄取,并提供与数据处理框架(如 Google Cloud 的 Dataflow 或 Amazon Web Services 的 Kinesis)的简单集成。这些仓库也更具弹性,因为它们将查询计算与存储层解耦49。数据保存在对象存储上,而不是本地磁盘,这使得我们可以独立地调整存储容量和查询的计算资源,正如我们之前在“云原生系统架构”中看到的那样。
开源数据仓库如 Apache Hive、Trino 和 Apache Spark 也随着云的发展而演变。随着分析数据存储转向对象存储上的数据湖,开源仓库开始分拆50。以下组件,之前在像 Apache Hive 这样的单一系统中集成,现在通常作为独立组件实现:
查询引擎
查询引擎如 Trino、Apache DataFusion 和 Presto 解析 SQL 查询,将其优化为执行计划,并在数据上执行这些计划。执行通常需要并行的分布式数据处理任务。一些查询引擎提供内置的任务执行,而其他则选择使用第三方执行框架,如 Apache Spark 或 Apache Flink。
存储格式
存储格式决定了表的行如何编码为文件中的字节,这些文件通常存储在对象存储或分布式文件系统中12。这些数据可以被查询引擎访问,也可以被使用数据湖的其他应用程序访问。这些存储格式的例子包括 Parquet、ORC、Lance 或 Nimble,我们将在下一节中看到更多关于它们的信息。
表格式
用 Apache Parquet 和类似存储格式写入的文件在写入后通常是不可变的。为了支持行的插入和删除,使用像 Apache Iceberg 或 Databricks 的 Delta 格式这样的表格式。表格式指定了一种文件格式,定义了哪些文件构成一个表以及该表的模式。这些格式还提供了高级功能,如时间旅行(能够查询表在过去某个时间点的状态)、垃圾回收,甚至事务。
数据目录
就像表格格式定义了哪些文件构成一个表一样,数据目录定义了哪些表构成一个数据库。目录用于创建、重命名和删除表。与存储和表格格式不同,像 Snowflake 的 Polaris 和 Databricks 的 Unity Catalog 这样的数据目录通常作为独立服务运行,可以通过 REST 接口进行查询。Apache Iceberg 也提供了一个目录,可以在客户端内部运行或作为单独的进程运行。查询引擎在读取和写入表时使用目录信息。传统上,目录和查询引擎是集成在一起的,但将它们解耦使得数据发现和数据治理系统(在“数据系统、法律与社会”中讨论)也能够访问目录的元数据。
列式存储
正如在“星型和雪花型:分析的模式”中讨论的,数据仓库通常使用关系模式,包含一个大的事实表,该表包含对维度表的外键引用。如果你的事实表中有万亿行和数 PB 的数据,如何高效地存储和查询这些数据就成了一个挑战性的问题。维度表通常要小得多(数百万行),因此在本节中我们将重点关注事实的存储。
尽管事实表通常有超过 100 列,但典型的数据仓库查询一次只访问其中的 4 或 5 列( "SELECT _" 查询在分析中很少需要)47。以示例 4-1 中的查询为例:它访问了大量行(2024 年日历年中每次有人购买水果或糖果的记录),但只需要访问 fact_sales 表中的三列: date_key 、 product_sk 和 quantity 。该查询忽略了所有其他列。
示例 4-1. 分析人们在一周的不同日子中更倾向于购买新鲜水果还是糖果
SELECT
dim_date.weekday, dim_product.category,
SUM(fact_sales.quantity) AS quantity_sold
FROM fact_sales
JOIN dim_date ON fact_sales.date_key = dim_date.date_key
JOIN dim_product ON fact_sales.product_sk = dim_product.product_sk
WHERE
dim_date.year = 2024 AND
dim_product.category IN ('Fresh fruit', 'Candy')
GROUP BY
dim_date.weekday, dim_product.category;我们如何高效地执行这个查询?
在大多数 OLTP 数据库中,存储是以行导向的方式布局的:表中一行的所有值是相邻存储的。文档数据库也是类似的:整个文档通常作为一个连续的字节序列存储。你可以在图 4-1 的 CSV 示例中看到这一点。
为了处理像示例 4-1 这样的查询,你可能在 fact_sales.date_key 和(或) fact_sales.product_sk 上有索引,这些索引告诉存储引擎在哪里找到特定日期或特定产品的所有销售记录。但是,行导向的存储引擎仍然需要将所有这些行(每行包含超过 100 个属性)从磁盘加载到内存中,解析它们,并过滤掉那些不符合要求条件的行。这可能需要很长时间。
列导向(或列式)存储的理念很简单:不要将一行的所有值一起存储,而是将每列的所有值一起存储。如果每列单独存储,查询只需要读取和解析在该查询中使用的那些列,这可以节省大量工作。图 4-7 使用图 3-5 中事实表的扩展版本展示了这一原则。

列导向的存储布局依赖于每一列以相同的顺序存储行。因此,如果您需要重新组装整行,可以从每个单独的列中取出第 23 个条目,并将它们组合在一起形成表的第 23 行。
事实上,列式存储引擎并不会一次性存储整个列(可能包含数万亿行)。相反,它们将表分解为数千或数百万行的块,并在每个块内分别存储每列的值54。由于许多查询限制在特定的日期范围内,因此通常会使每个块包含特定时间戳范围的行。查询只需加载在与所需日期范围重叠的块中所需的列。
列式存储如今几乎在所有分析数据库中都得到了应用54,从大型云数据仓库如 Snowflake55 到单节点嵌入式数据库如 DuckDB56,以及产品分析系统如 Pinot57 和 Druid58。它被用于存储格式如 Parquet、ORC5960、Lance61 和 Nimble62,以及内存分析格式如 Apache Arrow5963 和 Pandas/NumPy64。一些时间序列数据库,如 InfluxDB IOx65 和 TimescaleDB66,也基于列式存储。
列压缩
除了仅从磁盘加载查询所需的列外,我们还可以通过压缩数据进一步减少对磁盘吞吐量和网络带宽的需求。幸运的是,列式存储通常非常适合压缩。
看看图 4-7 中每列的值序列:它们往往看起来相当重复,这对压缩来说是一个好兆头。根据列中的数据,可以使用不同的压缩技术。在数据仓库中,一种特别有效的技术是位图编码,如图 4-8 所示。
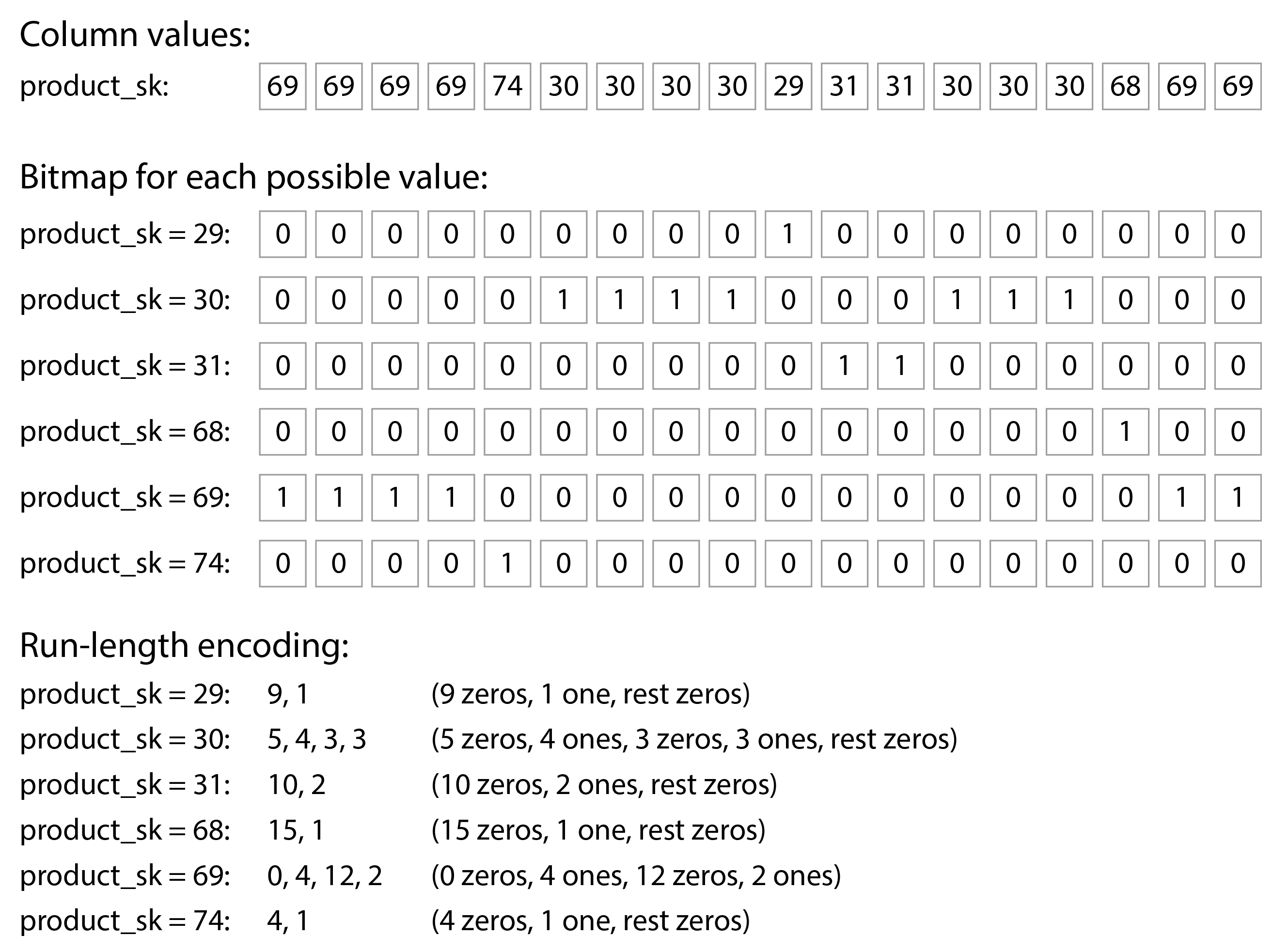
通常,列中的不同值数量与行数相比是很小的(例如,一个零售商可能有数十亿的销售交易,但只有 100,000 个不同的产品)。我们现在可以将一个具有 n 个不同值的列转换为 n 个单独的位图:每个不同值一个位图,每行一个位。该位为 1 表示该行具有该值,为 0 则表示没有。
一种选择是使用每行一个位来存储这些位图。然而,这些位图通常包含大量的零(我们称之为稀疏)。在这种情况下,位图还可以进行游程编码:计算连续的零或一的数量并存储该数量,如图 4-8 底部所示。像咆哮位图这样的技术在两种位图表示之间切换,使用最紧凑的表示方式67。这可以使列的编码变得非常高效。
这样的位图索引非常适合数据仓库中常见的查询类型。例如:
WHERE product_sk IN (31, 68, 69):
加载 product_sk = 31 、 product_sk = 68 和 product_sk = 69 的三个位图,并计算这三个位图的按位或,这可以非常高效地完成。
WHERE product_sk = 30 AND store_sk = 3:
加载 product_sk = 30 和 store_sk = 3 的位图,并计算按位与。这是可行的,因为列中的行是按相同顺序排列的,因此一列位图中的第 k 位对应于另一列位图中相同的行的第 k 位。
位图也可以用于回答图查询,例如查找社交网络中被用户 X 关注且同时关注用户 Y 的所有用户68。对于列式数据库,还有各种其他压缩方案,您可以在参考文献69 中找到。
注意
不要将列式数据库与宽列(也称为列族)数据模型混淆,在这种模型中,一行可以有数千列,并且所有行不需要具有相同的列9。尽管名称相似,宽列数据库是面向行的,因为它们将来自同一行的所有值存储在一起。Google 的 Bigtable、Apache Accumulo 和 HBase 是宽列模型的例子。
列存储中的排序顺序
在列存储中,行的存储顺序并不一定重要。最简单的方式是按照插入的顺序存储它们,因为这样插入新行只需在每一列后追加即可。然而,我们可以选择施加一个顺序,就像我们之前对 SSTables 所做的那样,并将其用作索引机制。
请注意,独立对每一列进行排序是没有意义的,因为那样我们将无法知道列中的哪些项属于同一行。我们只能重建一行,因为我们知道某一列中的第 k 项与另一列中的第 k 项属于同一行。
相反,数据需要按整行进行排序,尽管它是按列存储的。数据库管理员可以选择表格应按哪些列进行排序,利用他们对常见查询的了解。例如,如果查询经常针对日期范围,如上个月,那么将 date_key 作为第一个排序键可能是合理的。这样,查询只需扫描上个月的行,这比扫描所有行要快得多。
第二列可以确定任何在第一列中具有相同值的行的排序顺序。例如,如果 date_key 是图 4-7 中的第一个排序键,那么将 product_sk 作为第二个排序键可能是合理的,这样同一天的同一产品的所有销售记录就会在存储中分组在一起。这将有助于需要在特定日期范围内按产品对销售进行分组或过滤的查询。
另一个排序顺序的优点是它可以帮助压缩列。如果主排序列的不同值不多,那么在排序后,它将会有长序列,其中相同的值连续重复多次。像我们在图 4-8 中对位图使用的简单游程编码,可以将该列压缩到几千字节——即使表中有数十亿行。
这种压缩效果在第一个排序键上最强。第二和第三个排序键会更加杂乱,因此不会有如此长的重复值序列。排序优先级较低的列基本上以随机顺序出现,因此它们的压缩效果可能不如前面的列。但将前几列进行排序总体上仍然是一个优势。
写入列式存储
我们在“特征化事务处理和分析”中看到,数据仓库中的读取通常是对大量行的聚合;列式存储、压缩和排序都帮助加快这些读取查询。在数据仓库中的写入往往是数据的批量导入,通常通过 ETL 过程进行。
使用列式存储,在已排序表的中间写入单个行会非常低效,因为您必须从插入位置开始重写所有压缩列。然而,一次性批量写入多行可以摊销重写这些列的成本,从而提高效率。
日志结构的方法通常用于批量写入。所有写入首先进入一个面向行的、已排序的内存存储。当累积到足够的写入时,它们会与磁盘上的列编码文件合并,并批量写入新文件。由于旧文件保持不变,而新文件一次性写入,因此对象存储非常适合存储这些文件。
查询需要同时检查磁盘上的列数据和内存中的最近写入,并将两者结合起来。查询执行引擎将这种区别隐藏在用户面前。从分析师的角度来看,经过插入、更新或删除修改的数据会立即反映在后续查询中。Snowflake、Vertica、Apache Pinot、Apache Druid 等许多系统都这样做55575870。
查询执行:编译和向量化
一个复杂的 SQL 查询用于分析时被分解为一个查询计划,该计划由多个阶段组成,这些阶段称为操作符,可能分布在多台机器上以进行并行执行。查询规划器可以通过选择使用哪些操作符、以何种顺序执行它们以及在哪里运行每个操作符来进行大量优化。
在每个操作符内,查询引擎需要对列中的值执行各种操作,例如查找所有值在特定值集合中的行(可能作为连接的一部分),或检查值是否大于 15。它还需要查看同一行的多个列,例如查找所有销售交易,其中产品是香蕉且商店是特定的关注商店。
对于需要扫描数百万行的数据仓库查询,我们不仅需要关注它们从磁盘读取的数据量,还需要考虑执行复杂操作所需的 CPU 时间。最简单的操作符就像编程语言的解释器:在遍历每一行时,它检查一个表示查询的数据结构,以找出需要在哪些列上执行哪些比较或计算。不幸的是,这对于许多分析目的来说太慢了。为高效查询执行出现了两种替代方法71:
查询编译
查询引擎接收 SQL 查询并生成执行代码。该代码逐行迭代,查看感兴趣列中的值,执行所需的比较或计算,并在满足条件时将必要的值复制到输出缓冲区。查询引擎将生成的代码编译为机器代码(通常使用现有的编译器,如 LLVM),然后在已加载到内存中的列编码数据上运行。此代码生成方法类似于在 Java 虚拟机(JVM)和类似运行时中使用的即时编译(JIT)方法。
向量化处理
查询是被解释的,而不是编译的,但通过批量处理列中的多个值来加快速度,而不是逐行迭代。数据库内置了一组固定的预定义运算符;我们可以向它们传递参数并返回一批结果4569。
例如,我们可以将 product_sk 列和“香蕉”的 ID 传递给一个等式运算符,并返回一个位图(输入列中每个值对应一个位,如果是香蕉则为 1);然后我们可以将 store_sk 列和感兴趣商店的 ID 传递给同一个等式运算符,并返回另一个位图;接着我们可以将这两个位图传递给一个“按位与”运算符,如图 4-9 所示。结果将是一个位图,包含特定商店中所有香蕉销售的 1。

这两种方法在实现上非常不同,但在实践中都被使用71。两者都可以通过利用现代 CPU 的特性来实现非常好的性能:
-
更倾向于顺序内存访问而非随机访问,以减少缓存未命中72,
-
在紧密的内循环中完成大部分工作(即,使用少量指令且不进行函数调用),以保持 CPU 指令处理流水线的忙碌并避免分支预测错误,
-
直接在压缩数据上操作,而不将其解码为单独的内存表示,这样可以节省内存分配和复制成本。
物化视图和数据立方体
我们之前在“物化和更新时间线”中遇到过物化视图:在关系数据模型中,它们是类似表的对象,其内容是某些查询的结果。不同之处在于,物化视图是查询结果的实际副本,写入磁盘,而虚拟视图只是编写查询的快捷方式。当你从虚拟视图读取时,SQL 引擎会即时将其扩展为视图的基础查询,然后处理扩展后的查询。
当基础数据发生变化时,物化视图需要相应地更新。一些数据库可以自动完成这一点,还有一些系统,如 Materialize,专门从事物化视图的维护75。执行这样的更新意味着写入时需要更多的工作,但物化视图可以提高在重复执行相同查询的工作负载中的读取性能。
物化聚合是一种物化视图,在数据仓库中非常有用。如前所述,数据仓库查询通常涉及聚合函数,例如 SQL 中的 COUNT 、 SUM 、 AVG 、 MIN 或 MAX 。如果许多不同的查询使用相同的聚合,那么每次都从原始数据中计算这些聚合将是浪费。为什么不缓存一些查询最常用的计数或总和呢?数据立方体或 OLAP 立方体通过创建一个按不同维度分组的聚合网格来实现这一点76。图 4-10 显示了一个示例。
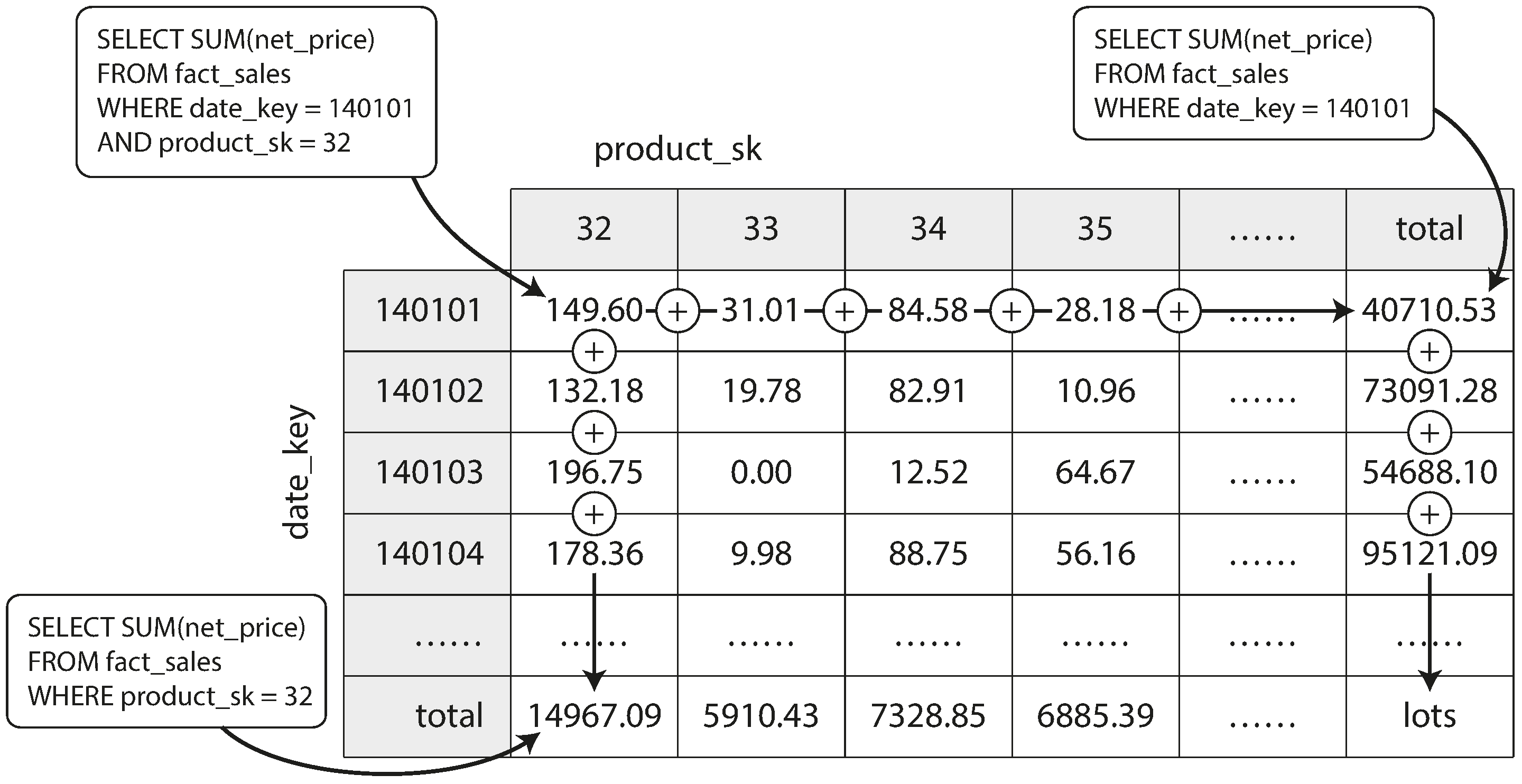
现在假设每个事实只与两个维度表有外键关系——在图 4-10 中,这些是 date_key 和 product_sk 。您现在可以绘制一个二维表格,一条轴上是日期,另一条轴上是产品。每个单元格包含所有具有该日期-产品组合的事实的一个属性(例如, net_price )的聚合(例如, SUM )。然后,您可以沿着每一行或每一列应用相同的聚合,从而获得一个减少了一个维度的摘要(无论日期的产品销售,或无论产品的日期销售)。
一般来说,事实通常具有超过两个维度。在图 3-5 中,有五个维度:日期、产品、商店、促销和客户。想象一个五维超立方体的样子要困难得多,但原则是相同的:每个单元格包含特定日期-产品-商店-促销-客户组合的销售额。这些值可以沿着每个维度反复进行汇总。
物化数据立方体的优势在于某些查询变得非常快速,因为它们实际上已经被预计算。例如,如果你想知道昨天每个商店的总销售额,你只需查看相应维度的总数——无需扫描数百万行。
缺点是数据立方体没有像查询原始数据那样的灵活性。例如,无法计算销售中有多少比例来自于价格超过 100 美元的商品,因为价格并不是其中一个维度。因此,大多数数据仓库尽量保留尽可能多的原始数据,并仅将聚合(如数据立方体)用作某些查询的性能提升。
多维和全文索引
我们在本章前半部分看到的 B 树和 LSM 树允许对单个属性进行范围查询:例如,如果键是用户名,您可以将它们用作索引,以高效地找到所有以 L 开头的名称。但有时,仅通过单个属性进行搜索是不够的。
最常见的多列索引类型称为连接索引,它通过将一个字段附加到另一个字段来简单地将几个字段组合成一个键(索引定义指定字段连接的顺序)。这就像一本老式的纸质电话簿,它提供了从(姓,名)到电话号码的索引。由于排序顺序,该索引可以用来查找所有具有特定姓氏的人,或所有具有特定姓氏-名字组合的人。然而,如果您想查找所有具有特定名字的人,则该索引就毫无用处。
另一方面,多维索引允许您一次查询多个列。这在地理空间数据中尤为重要。例如,一个餐厅搜索网站可能有一个数据库,包含每个餐厅的纬度和经度。当用户在地图上查看餐厅时,网站需要搜索用户当前查看的矩形地图区域内的所有餐厅。这需要一个二维范围查询,如下所示:
SELECT \* FROM restaurants WHERE latitude > 51.4946 AND latitude < 51.5079
AND longitude > -0.1162 AND longitude < -0.1004;对纬度和经度列的连接索引无法有效地回答这种查询:它可以给您一个纬度范围内的所有餐厅(但在任何经度上),或者一个经度范围内的所有餐厅(但在南北极之间的任何地方),但不能同时满足这两者。
一种选择是使用空间填充曲线将二维位置转换为单个数字,然后使用常规的 B 树索引77。更常见的是使用专门的空间索引,如 R 树或 Bkd 树78;它们将空间划分,使得相邻的数据点倾向于被分组在同一个子树中。例如,PostGIS 使用 PostgreSQL 的广义搜索树索引功能实现了作为 R 树的地理空间索引79。还可以使用规则间隔的三角形、正方形或六边形网格80。
多维索引不仅仅用于地理位置。例如,在一个电子商务网站上,你可以使用一个三维索引来搜索某一范围颜色的产品,维度为(红色、绿色、蓝色);或者在一个天气观测数据库中,你可以在(日期、温度)上建立一个二维索引,以便高效地搜索 2013 年所有温度在 25 到 30℃ 之间的观测记录。使用一维索引时,你必须要么扫描 2013 年的所有记录(不考虑温度),然后按温度过滤,要么反之。二维索引可以同时按时间戳和温度进行缩小范围81。
全文搜索
全文搜索允许您通过可能出现在文本中的关键字搜索一组文本文件(网页、产品描述等)82。信息检索是一个庞大且专业的主题,通常涉及特定语言的处理:例如,几种亚洲语言在单词之间没有空格或标点符号,因此将文本拆分为单词需要一个模型来指示哪些字符序列构成一个单词。全文搜索通常还涉及匹配相似但不完全相同的单词(例如拼写错误或单词的不同语法形式)和同义词。这些问题超出了本书的范围。
然而,从本质上讲,您可以将全文搜索视为另一种多维查询:在这种情况下,可能出现在文本中的每个单词(术语)都是一个维度。包含术语 x 的文档在维度 x 中的值为 1,而不包含 x 的文档在维度 x 中的值为 0。搜索提到“红色苹果”的文档意味着一个查询,它在红色维度中寻找 1,同时在苹果维度中寻找 1。因此,维度的数量可能非常大。
许多搜索引擎用来回答此类查询的数据结构称为倒排索引。这是一种键值结构,其中键是一个术语,值是包含该术语的所有文档的 ID 列表(发布列表)。如果文档 ID 是连续的数字,则发布列表也可以表示为稀疏位图,如图 4-8 所示:位图中术语 x 的第 n 位为 1,如果 ID 为 n 的文档包含术语 x83。
查找同时包含术语 x 和 y 的所有文档现在类似于一个向量化的数据仓库查询,该查询搜索匹配两个条件的行(图 4-9):加载术语 x 和 y 的两个位图并计算它们的按位与。即使位图是运行长度编码的,这也可以非常高效地完成。
例如,Lucene,这是 Elasticsearch 和 Solr 使用的全文索引引擎,工作原理如下84。它将术语到文档列表的映射存储在类似 SSTable 的排序文件中,这些文件在后台使用我们在本章前面看到的相同日志结构方法进行合并85。PostgreSQL 的 GIN 索引类型也使用文档列表来支持全文搜索和 JSON 文档内部的索引8687。
除了将文本拆分为单词外,另一种方法是查找所有长度为 n 的子字符串,这些子字符串称为 n-grams。例如,字符串 "hello" 的三元组(n = 3)是 "hel" 、 "ell" 和 "llo" 。如果我们构建所有三元组的倒排索引,我们可以搜索文档中任意长度至少为三个字符的子字符串。三元组索引甚至允许在搜索查询中使用正则表达式;缺点是它们的体积相当大88。
为了应对文档或查询中的拼写错误,Lucene 能够在一定的编辑距离内搜索文本中的单词(编辑距离为 1 意味着添加、删除或替换了一个字母)89。它通过将术语集存储为字符上的有限状态自动机,类似于前缀树90,并将其转换为 Levenshtein 自动机,从而支持在给定编辑距离内高效搜索单词91。
向量嵌入
语义搜索超越了同义词和拼写错误,试图理解文档概念和用户意图。例如,如果您的帮助页面包含一个标题为“取消订阅”的页面,当用户搜索“如何关闭我的账户”或“终止合同”时,仍然应该能够找到该页面,因为这些词在意义上是相近的,尽管它们使用了完全不同的词。
为了理解文档的语义——即其含义——语义搜索索引使用嵌入模型将文档转换为一个浮点值的向量,称为向量嵌入。该向量表示多维空间中的一个点,每个浮点值表示文档在某一维度轴上的位置。当嵌入的输入文档在语义上相似时,嵌入模型生成的向量嵌入在这个多维空间中彼此接近。
注意
我们在“查询执行:编译和向量化”中看到了向量化处理这个术语。在语义搜索中,向量有不同的含义。在向量化处理过程中,向量指的是可以使用特别优化的代码处理的一批位。在嵌入模型中,向量是一组浮点数,表示多维空间中的一个位置。
例如,关于农业的维基百科页面的三维向量嵌入可能是 [0.1, 0.22, 0.11]。关于蔬菜的维基百科页面会非常接近,也许嵌入为 [0.13, 0.19, 0.24]。关于星型模式的页面可能有一个嵌入 [0.82, 0.39, -0.74],相对较远。我们可以通过观察得出前两个向量比第三个更接近。
嵌入模型使用更大的向量(通常超过 1,000 个数字),但原理是相同的。我们并不试图理解每个数字的含义;它们只是嵌入模型指向抽象多维空间中某个位置的一种方式。搜索引擎使用距离函数,如余弦相似度或欧几里得距离,来测量向量之间的距离。余弦相似度通过测量两个向量的夹角余弦来确定它们的接近程度,而欧几里得距离则测量空间中两点之间的直线距离。
许多早期的嵌入模型,如 Word2Vec92、BERT93和 GPT94,主要处理文本数据。这些模型通常以神经网络的形式实现。研究人员还创建了用于视频、音频和图像的嵌入模型。最近,模型架构变得多模态:单个模型可以为多种模态(如文本和图像)生成向量嵌入。
语义搜索引擎使用嵌入模型在用户输入查询时生成向量嵌入。用户的查询和相关上下文(如用户的位置)被输入到嵌入模型中。在嵌入模型生成查询的向量嵌入后,搜索引擎必须使用向量索引找到具有相似向量嵌入的文档。
向量索引存储一组文档的向量嵌入。要查询索引,您需要传入查询的向量嵌入,索引将返回与查询向量最接近的文档。由于我们之前看到的 R 树不适合处理高维向量,因此使用了专门的向量索引,例如:
平面索引
向量以原样存储在索引中。查询必须读取每个向量并测量其与查询向量的距离。平面索引是准确的,但测量查询与每个向量之间的距离很慢。
倒排文件(IVF)索引
向量空间被聚类成多个分区(称为质心),以减少必须比较的向量数量。IVF 索引比平面索引更快,但只能提供近似结果:查询和文档可能落在不同的分区中,即使它们彼此接近。IVF 索引上的查询首先定义探针,探针只是要检查的分区数量。使用更多探针的查询将更准确,但会更慢,因为必须比较更多的向量。
分层可导航小世界(HNSW) HNSW 索引维护多个层次的向量空间,如图 4-11 所示。每一层被表示为一个图,其中节点代表向量,边代表与附近向量的接近程度。查询从定位最上层中最近的向量开始,该层的节点数量较少。然后,查询移动到下层的相同节点,并沿着该层中更密集连接的边查找与查询向量更接近的向量。这个过程持续进行,直到到达最后一层。与 IVF 索引一样,HNSW 索引也是近似的。

许多流行的向量数据库实现了 IVF 和 HNSW 索引。Facebook 的 Faiss 库有许多每种索引的变体95,而 PostgreSQL 的 pgvector 也支持这两种索引96。IVF 和 HNSW 算法的完整细节超出了本书的范围,但它们的论文是一个很好的资源9798。
总结
在本章中,我们试图深入了解数据库如何进行存储和检索。当你将数据存储在数据库中时会发生什么,以及当你稍后查询这些数据时数据库会做什么?
“分析系统与操作系统”介绍了事务处理(OLTP)和分析(OLAP)之间的区别。在本章中,我们看到针对 OLTP 优化的存储引擎与针对分析优化的存储引擎有很大的不同:
-
OLTP 系统针对高请求量进行了优化,每个请求读取和写入少量记录,并且需要快速响应。记录通常通过主键或辅助索引访问,这些索引通常是从键到记录的有序映射,同时也支持范围查询。
-
数据仓库和类似的分析系统针对复杂的读取查询进行了优化,这些查询会扫描大量记录。它们通常使用列式存储布局,并进行压缩,以最小化此类查询从磁盘读取的数据量,并通过即时编译查询或向量化来最小化处理数据所花费的 CPU 时间。
在 OLTP 方面,我们看到了两种主要思想流派的存储引擎:
-
日志结构化方法,仅允许向文件追加内容和删除过时文件,但从不更新已写入的文件。SSTables、LSM 树、RocksDB、Cassandra、HBase、Scylla、Lucene 等都属于这一组。一般来说,日志结构化存储引擎倾向于提供高写入吞吐量。
-
就地更新方法,将磁盘视为一组可以被覆盖的固定大小页面。B 树是这一理念的最大例子,广泛应用于所有主要的关系型 OLTP 数据库以及许多非关系型数据库。作为经验法则,B 树在读取方面通常表现更好,提供比日志结构化存储更高的读取吞吐量和更低的响应时间。
我们接着看了一下可以同时搜索多个条件的索引:多维索引,例如 R 树,可以同时通过经纬度在地图上搜索点,以及全文搜索索引,可以搜索出现在同一文本中的多个关键字。最后,向量数据库用于对文本文件和其他媒体进行语义搜索;它们使用维度更大的向量,通过比较向量相似性来找到相似的文档。
作为应用程序开发者,如果你掌握了关于存储引擎内部结构的这些知识,你将更好地了解哪个工具最适合你的特定应用。如果你需要调整数据库的调优参数,这种理解使你能够想象更高或更低的值可能产生的影响。
尽管本章无法让你成为某个特定存储引擎调优的专家,但希望它能为你提供足够的词汇和思路,使你能够理解所选数据库的文档。
参考文献
Footnotes
-
Nikolay Samokhvalov. How partial, covering, and multicolumn indexes may slow down UPDATEs in PostgreSQL. postgres.ai, October 2021. Archived at perma.cc/PBK3-F4G9 ↩
-
Goetz Graefe. Modern B-Tree Techniques. Foundations and Trends in Databases, volume 3, issue 4, pages 203–402, August 2011. doi:10.1561/1900000028 ↩ ↩2
-
Evan Jones. Why databases use ordered indexes but programming uses hash tables. evanjones.ca, December 2019. Archived at perma.cc/NJX8-3ZZD ↩
-
Branimir Lambov. CEP-25: Trie-indexed SSTable format. cwiki.apache.org, November 2022. Archived at perma.cc/HD7W-PW8U. Linked Google Doc archived at perma.cc/UL6C-AAAE ↩
-
Thomas H. Cormen, Charles E. Leiserson, Ronald L. Rivest, and Clifford Stein: Introduction to Algorithms, 3rd edition. MIT Press, 2009. ISBN: 978-0-262-53305-8 ↩ ↩2 ↩3
-
Branimir Lambov. Trie Memtables in Cassandra. Proceedings of the VLDB Endowment, volume 15, issue 12, pages 3359–3371, August 2022. doi:10.14778/3554821.3554828 ↩
-
Dhruba Borthakur. The History of RocksDB. rocksdb.blogspot.com, November 2013. Archived at perma.cc/Z7C5-JPSP ↩
-
Matteo Bertozzi. Apache HBase I/O – HFile. blog.cloudera.com, June 2012. Archived at perma.cc/U9XH-L2KL ↩
-
Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach, Mike Burrows, Tushar Chandra, Andrew Fikes, and Robert E. Gruber. Bigtable: A Distributed Storage System for Structured Data. At 7th USENIX Symposium on Operating System Design and Implementation (OSDI), November 2006. ↩ ↩2
-
Patrick O’Neil, Edward Cheng, Dieter Gawlick, and Elizabeth O’Neil. The Log-Structured Merge-Tree (LSM-Tree). Acta Informatica, volume 33, issue 4, pages 351–385, June 1996. doi:10.1007/s002360050048 ↩
-
Mendel Rosenblum and John K. Ousterhout. The Design and Implementation of a Log-Structured File System. ACM Transactions on Computer Systems, volume 10, issue 1, pages 26–52, February 1992. doi:10.1145/146941.146943 ↩
-
Michael Armbrust, Tathagata Das, Liwen Sun, Burak Yavuz, Shixiong Zhu, Mukul Murthy, Joseph Torres, Herman van Hovell, Adrian Ionescu, Alicja Łuszczak, Michał Świtakowski, Michał Szafrański, Xiao Li, Takuya Ueshin, Mostafa Mokhtar, Peter Boncz, Ali Ghodsi, Sameer Paranjpye, Pieter Senster, Reynold Xin, and Matei Zaharia. Delta Lake: High-Performance ACID Table Storage over Cloud Object Stores. Proceedings of the VLDB Endowment, volume 13, issue 12, pages 3411–3424, August 2020. doi:10.14778/3415478.3415560 ↩ ↩2
-
Burton H. Bloom. Space/Time Trade-offs in Hash Coding with Allowable Errors. Communications of the ACM, volume 13, issue 7, pages 422–426, July 1970. doi:10.1145/362686.362692 ↩
-
Adam Kirsch and Michael Mitzenmacher. Less Hashing, Same Performance: Building a Better Bloom Filter. Random Structures & Algorithms, volume 33, issue 2, pages 187–218, September 2008. doi:10.1002/rsa.20208 ↩
-
Thomas Hurst. Bloom Filter Calculator. hur.st, September 2023. Archived at perma.cc/L3AV-6VC2 ↩
-
Chen Luo and Michael J. Carey. LSM-based storage techniques: a survey. The VLDB Journal, volume 29, pages 393–418, July 2019. doi:10.1007/s00778-019-00555-y ↩
-
Mark Callaghan. Name that compaction algorithm. smalldatum.blogspot.com, August 2018. Archived at perma.cc/CN4M-82DY ↩
-
Prashanth Rao. Embedded databases (1): The harmony of DuckDB, KùzuDB and LanceDB. thedataquarry.com, August 2023. Archived at perma.cc/PA28-2R35 ↩
-
Hacker News discussion. Bluesky migrates to single-tenant SQLite. news.ycombinator.com, October 2023. Archived at perma.cc/69LM-5P6X ↩
-
Rudolf Bayer and Edward M. McCreight. Organization and Maintenance of Large Ordered Indices. Boeing Scientific Research Laboratories, Mathematical and Information Sciences Laboratory, report no. 20, July 1970. doi:10.1145/1734663.1734671 ↩
-
Douglas Comer. The Ubiquitous B-Tree. ACM Computing Surveys, volume 11, issue 2, pages 121–137, June 1979. doi:10.1145/356770.356776 ↩
-
Hironobu Suzuki. The Internals of PostgreSQL. interdb.jp, 2017. ↩ ↩2
-
Manos Athanassoulis, Michael S. Kester, Lukas M. Maas, Radu Stoica, Stratos Idreos, Anastasia Ailamaki, and Mark Callaghan. Designing Access Methods: The RUM Conjecture. At 19th International Conference on Extending Database Technology (EDBT), March 2016. doi:10.5441/002/edbt.2016.42 ↩
-
Ben Stopford. Log Structured Merge Trees. benstopford.com, February 2015. Archived at perma.cc/E5BV-KUJ6 ↩
-
Mark Callaghan. The Advantages of an LSM vs a B-Tree. smalldatum.blogspot.co.uk, January 2016. Archived at perma.cc/3TYZ-EFUD ↩
-
Oana Balmau, Florin Dinu, Willy Zwaenepoel, Karan Gupta, Ravishankar Chandhiramoorthi, and Diego Didona. SILK: Preventing Latency Spikes in Log-Structured Merge Key-Value Stores. At USENIX Annual Technical Conference, July 2019. ↩
-
Igor Canadi, Siying Dong, Mark Callaghan, et al. RocksDB Tuning Guide. github.com, 2023. Archived at perma.cc/UNY4-MK6C ↩
-
Gabriel Haas and Viktor Leis. What Modern NVMe Storage Can Do, and How to Exploit it: High-Performance I/O for High-Performance Storage Engines. Proceedings of the VLDB Endowment, volume 16, issue 9, pages 2090-2102. doi:10.14778/3598581.3598584 ↩
-
Emmanuel Goossaert. Coding for SSDs. codecapsule.com, February 2014. ↩
-
Jack Vanlightly. Is sequential IO dead in the era of the NVMe drive? jack-vanlightly.com, May 2023. Archived at perma.cc/7TMZ-TAPU ↩
-
Alibaba Cloud Storage Team. Storage System Design Analysis: Factors Affecting NVMe SSD Performance (2). alibabacloud.com, January 2019. Archived at archive.org ↩
-
Xiao-Yu Hu and Robert Haas. The Fundamental Limit of Flash Random Write Performance: Understanding, Analysis and Performance Modelling. dominoweb.draco.res.ibm.com, March 2010. Archived at perma.cc/8JUL-4ZDS ↩
-
Lanyue Lu, Thanumalayan Sankaranarayana Pillai, Andrea C. Arpaci-Dusseau, and Remzi H. Arpaci-Dusseau. WiscKey: Separating Keys from Values in SSD-conscious Storage. At 4th USENIX Conference on File and Storage Technologies (FAST), February 2016. ↩
-
Peter Zaitsev. Innodb Double Write. percona.com, August 2006. Archived at perma.cc/NT4S-DK7T ↩
-
Tomas Vondra. On the Impact of Full-Page Writes. 2ndquadrant.com, November 2016. Archived at perma.cc/7N6B-CVL3 ↩
-
Mark Callaghan. Read, write & space amplification - B-Tree vs LSM. smalldatum.blogspot.com, November 2015. Archived at perma.cc/S487-WK5P ↩ ↩2
-
Mark Callaghan. Choosing Between Efficiency and Performance with RocksDB. At Code Mesh, November 2016. Video at youtube.com/watch?v=tgzkgZVXKB4 ↩
-
Subhadeep Sarkar, Tarikul Islam Papon, Dimitris Staratzis, Zichen Zhu, and Manos Athanassoulis. Enabling Timely and Persistent Deletion in LSM-Engines. ACM Transactions on Database Systems, volume 48, issue 3, article no. 8, August 2023. doi:10.1145/3599724 ↩
-
Drew Silcock. How Postgres stores data on disk – this one’s a page turner. drew.silcock.dev, August 2024. Archived at perma.cc/8K7K-7VJ2 ↩
-
Joe Webb. Using Covering Indexes to Improve Query Performance. simple-talk.com, September 2008. Archived at perma.cc/6MEZ-R5VR ↩
-
Michael Stonebraker, Samuel Madden, Daniel J. Abadi, Stavros Harizopoulos, Nabil Hachem, and Pat Helland. The End of an Architectural Era (It’s Time for a Complete Rewrite). At 33rd International Conference on Very Large Data Bases (VLDB), September 2007. ↩
-
VoltDB Technical Overview White Paper. VoltDB, 2017. Archived at perma.cc/B9SF-SK5G ↩
-
Stephen M. Rumble, Ankita Kejriwal, and John K. Ousterhout. Log-Structured Memory for DRAM-Based Storage. At 12th USENIX Conference on File and Storage Technologies (FAST), February 2014. ↩
-
Stavros Harizopoulos, Daniel J. Abadi, Samuel Madden, and Michael Stonebraker. OLTP Through the Looking Glass, and What We Found There. At ACM International Conference on Management of Data (SIGMOD), June 2008. doi:10.1145/1376616.1376713 ↩
-
Per-Åke Larson, Cipri Clinciu, Campbell Fraser, Eric N. Hanson, Mostafa Mokhtar, Michal Nowakiewicz, Vassilis Papadimos, Susan L. Price, Srikumar Rangarajan, Remus Rusanu, and Mayukh Saubhasik. Enhancements to SQL Server Column Stores. At ACM International Conference on Management of Data (SIGMOD), June 2013. doi:10.1145/2463676.2463708 ↩ ↩2
-
Franz Färber, Norman May, Wolfgang Lehner, Philipp Große, Ingo Müller, Hannes Rauhe, and Jonathan Dees. The SAP HANA Database – An Architecture Overview. IEEE Data Engineering Bulletin, volume 35, issue 1, pages 28–33, March 2012. ↩
-
Michael Stonebraker. The Traditional RDBMS Wisdom Is (Almost Certainly) All Wrong. Presentation at EPFL, May 2013. ↩ ↩2
-
Adam Prout, Szu-Po Wang, Joseph Victor, Zhou Sun, Yongzhu Li, Jack Chen, Evan Bergeron, Eric Hanson, Robert Walzer, Rodrigo Gomes, and Nikita Shamgunov. Cloud-Native Transactions and Analytics in SingleStore. At ACM International Conference on Management of Data (SIGMOD), June 2022. doi:10.1145/3514221.3526055 ↩
-
Tino Tereshko and Jordan Tigani. BigQuery under the hood. cloud.google.com, January 2016. Archived at perma.cc/WP2Y-FUCF ↩
-
Wes McKinney. The Road to Composable Data Systems: Thoughts on the Last 15 Years and the Future. wesmckinney.com, September 2023. Archived at perma.cc/6L2M-GTJX ↩
-
Julien Le Dem. Dremel Made Simple with Parquet. blog.twitter.com, September 2013. ↩
-
Sergey Melnik, Andrey Gubarev, Jing Jing Long, Geoffrey Romer, Shiva Shivakumar, Matt Tolton, and Theo Vassilakis. Dremel: Interactive Analysis of Web-Scale Datasets. At 36th International Conference on Very Large Data Bases (VLDB), pages 330–339, September 2010. doi:10.14778/1920841.1920886 ↩
-
Joe Kearney. Understanding Record Shredding: storing nested data in columns. joekearney.co.uk, December 2016. Archived at perma.cc/ZD5N-AX5D ↩
-
Jamie Brandon. A shallow survey of OLAP and HTAP query engines. scattered-thoughts.net, September 2023. Archived at perma.cc/L3KH-J4JF ↩ ↩2
-
Benoit Dageville, Thierry Cruanes, Marcin Zukowski, Vadim Antonov, Artin Avanes, Jon Bock, Jonathan Claybaugh, Daniel Engovatov, Martin Hentschel, Jiansheng Huang, Allison W. Lee, Ashish Motivala, Abdul Q. Munir, Steven Pelley, Peter Povinec, Greg Rahn, Spyridon Triantafyllis, and Philipp Unterbrunner. The Snowflake Elastic Data Warehouse. At ACM International Conference on Management of Data (SIGMOD), pages 215–226, June 2016. doi:10.1145/2882903.2903741 ↩ ↩2
-
Mark Raasveldt and Hannes Mühleisen. Data Management for Data Science Towards Embedded Analytics. At 10th Conference on Innovative Data Systems Research (CIDR), January 2020. ↩
-
Jean-François Im, Kishore Gopalakrishna, Subbu Subramaniam, Mayank Shrivastava, Adwait Tumbde, Xiaotian Jiang, Jennifer Dai, Seunghyun Lee, Neha Pawar, Jialiang Li, and Ravi Aringunram. Pinot: Realtime OLAP for 530 Million Users. At ACM International Conference on Management of Data (SIGMOD), pages 583–594, May 2018. doi:10.1145/3183713.3190661 ↩ ↩2
-
Fangjin Yang, Eric Tschetter, Xavier Léauté, Nelson Ray, Gian Merlino, and Deep Ganguli. Druid: A Real-time Analytical Data Store. At ACM International Conference on Management of Data (SIGMOD), June 2014. doi:10.1145/2588555.2595631 ↩ ↩2
-
Chunwei Liu, Anna Pavlenko, Matteo Interlandi, and Brandon Haynes. Deep Dive into Common Open Formats for Analytical DBMSs. Proceedings of the VLDB Endowment, volume 16, issue 11, pages 3044–3056, July 2023. doi:10.14778/3611479.3611507 ↩ ↩2
-
Xinyu Zeng, Yulong Hui, Jiahong Shen, Andrew Pavlo, Wes McKinney, and Huanchen Zhang. An Empirical Evaluation of Columnar Storage Formats. Proceedings of the VLDB Endowment, volume 17, issue 2, pages 148–161. doi:10.14778/3626292.3626298 ↩
-
Weston Pace. Lance v2: A columnar container format for modern data. blog.lancedb.com, April 2024. Archived at perma.cc/ZK3Q-S9VJ ↩
-
Yoav Helfman. Nimble, A New Columnar File Format. At VeloxCon, April 2024. ↩
-
Wes McKinney. Apache Arrow: High-Performance Columnar Data Framework. At CMU Database Group – Vaccination Database Tech Talks, December 2021. ↩
-
Wes McKinney. Python for Data Analysis, 3rd Edition. O’Reilly Media, August 2022. ISBN: 9781098104023 ↩
-
Paul Dix. The Design of InfluxDB IOx: An In-Memory Columnar Database Written in Rust with Apache Arrow. At CMU Database Group – Vaccination Database Tech Talks, May 2021. ↩
-
Carlota Soto and Mike Freedman. Building Columnar Compression for Large PostgreSQL Databases. timescale.com, March 2024. Archived at perma.cc/7KTF-V3EH ↩
-
Daniel Lemire, Gregory Ssi‐Yan‐Kai, and Owen Kaser. Consistently faster and smaller compressed bitmaps with Roaring. Software: Practice and Experience, volume 46, issue 11, pages 1547–1569, November 2016. doi:10.1002/spe.2402 ↩
-
Jaz Volpert. An entire Social Network in 1.6GB (GraphD Part 2). jazco.dev, April 2024. Archived at perma.cc/L27Z-QVMG ↩
-
Daniel J. Abadi, Peter Boncz, Stavros Harizopoulos, Stratos Idreos, and Samuel Madden. The Design and Implementation of Modern Column-Oriented Database Systems. Foundations and Trends in Databases, volume 5, issue 3, pages 197–280, December 2013. doi:10.1561/1900000024 ↩ ↩2
-
Andrew Lamb, Matt Fuller, Ramakrishna Varadarajan, Nga Tran, Ben Vandiver, Lyric Doshi, and Chuck Bear. The Vertica Analytic Database: C-Store 7 Years Later. Proceedings of the VLDB Endowment, volume 5, issue 12, pages 1790–1801, August 2012. doi:10.14778/2367502.2367518 ↩
-
Timo Kersten, Viktor Leis, Alfons Kemper, Thomas Neumann, Andrew Pavlo, and Peter Boncz. Everything You Always Wanted to Know About Compiled and Vectorized Queries But Were Afraid to Ask. Proceedings of the VLDB Endowment, volume 11, issue 13, pages 2209–2222, September 2018. doi:10.14778/3275366.3284966 ↩ ↩2
-
Forrest Smith. Memory Bandwidth Napkin Math. forrestthewoods.com, February 2020. Archived at perma.cc/Y8U4-PS7N ↩
-
Peter Boncz, Marcin Zukowski, and Niels Nes. MonetDB/X100: Hyper-Pipelining Query Execution. At 2nd Biennial Conference on Innovative Data Systems Research (CIDR), January 2005. ↩
-
Jingren Zhou and Kenneth A. Ross. Implementing Database Operations Using SIMD Instructions. At ACM International Conference on Management of Data (SIGMOD), pages 145–156, June 2002. doi:10.1145/564691.564709 ↩
-
Kevin Bartley. OLTP Queries: Transfer Expensive Workloads to Materialize. materialize.com, August 2024. Archived at perma.cc/4TYM-TYD8 ↩
-
Jim Gray, Surajit Chaudhuri, Adam Bosworth, Andrew Layman, Don Reichart, Murali Venkatrao, Frank Pellow, and Hamid Pirahesh. Data Cube: A Relational Aggregation Operator Generalizing Group-By, Cross-Tab, and Sub-Totals. Data Mining and Knowledge Discovery, volume 1, issue 1, pages 29–53, March 2007. doi:10.1023/A:1009726021843 ↩
-
Frank Ramsak, Volker Markl, Robert Fenk, Martin Zirkel, Klaus Elhardt, and Rudolf Bayer. Integrating the UB-Tree into a Database System Kernel. At 26th International Conference on Very Large Data Bases (VLDB), September 2000. ↩
-
Octavian Procopiuc, Pankaj K. Agarwal, Lars Arge, and Jeffrey Scott Vitter. Bkd-Tree: A Dynamic Scalable kd-Tree. At 8th International Symposium on Spatial and Temporal Databases (SSTD), pages 46–65, July 2003. doi:10.1007/978-3-540-45072-6_4 ↩
-
Joseph M. Hellerstein, Jeffrey F. Naughton, and Avi Pfeffer. Generalized Search Trees for Database Systems. At 21st International Conference on Very Large Data Bases (VLDB), September 1995. ↩
-
Isaac Brodsky. H3: Uber’s Hexagonal Hierarchical Spatial Index. eng.uber.com, June 2018. Archived at archive.org ↩
-
Robert Escriva, Bernard Wong, and Emin Gün Sirer. HyperDex: A Distributed, Searchable Key-Value Store. At ACM SIGCOMM Conference, August 2012. doi:10.1145/2377677.2377681 ↩
-
Christopher D. Manning, Prabhakar Raghavan, and Hinrich Schütze. Introduction to Information Retrieval. Cambridge University Press, 2008. ISBN: 978-0-521-86571-5, available online at nlp.stanford.edu/IR-book ↩
-
Jianguo Wang, Chunbin Lin, Yannis Papakonstantinou, and Steven Swanson. An Experimental Study of Bitmap Compression vs. Inverted List Compression. At ACM International Conference on Management of Data (SIGMOD), pages 993–1008, May 2017. doi:10.1145/3035918.3064007 ↩
-
Adrien Grand. What is in a Lucene Index? At Lucene/Solr Revolution, November 2013. Archived at perma.cc/Z7QN-GBYY ↩
-
Michael McCandless. Visualizing Lucene’s Segment Merges. blog.mikemccandless.com, February 2011. Archived at perma.cc/3ZV8-72W6 ↩
-
Lukas Fittl. Understanding Postgres GIN Indexes: The Good and the Bad. pganalyze.com, December 2021. Archived at perma.cc/V3MW-26H6 ↩
-
Jimmy Angelakos. The State of (Full) Text Search in PostgreSQL 12. At FOSDEM, February 2020. Archived at perma.cc/J6US-3WZS ↩
-
Alexander Korotkov. Index support for regular expression search. At PGConf.EU Prague, October 2012. Archived at perma.cc/5RFZ-ZKDQ ↩
-
Michael McCandless. Lucene’s FuzzyQuery Is 100 Times Faster in 4.0. blog.mikemccandless.com, March 2011. Archived at perma.cc/E2WC-GHTW ↩
-
Steffen Heinz, Justin Zobel, and Hugh E. Williams. Burst Tries: A Fast, Efficient Data Structure for String Keys. ACM Transactions on Information Systems, volume 20, issue 2, pages 192–223, April 2002. doi:10.1145/506309.506312 ↩
-
Klaus U. Schulz and Stoyan Mihov. Fast String Correction with Levenshtein Automata. International Journal on Document Analysis and Recognition, volume 5, issue 1, pages 67–85, November 2002. doi:10.1007/s10032-002-0082-8 ↩
-
Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. Efficient Estimation of Word Representations in Vector Space. At International Conference on Learning Representations (ICLR), May 2013. doi:10.48550/arXiv.1301.3781 ↩
-
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. At Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, volume 1, pages 4171–4186, June 2019. doi:10.18653/v1/N19-1423 ↩
-
Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. Improving Language Understanding by Generative Pre-Training. openai.com, June 2018. Archived at perma.cc/5N3C-DJ4C ↩
-
Matthijs Douze, Maria Lomeli, and Lucas Hosseini. Faiss indexes. github.com, August 2024. Archived at perma.cc/2EWG-FPBS ↩
-
Varik Matevosyan. Understanding pgvector’s HNSW Index Storage in Postgres. lantern.dev, August 2024. Archived at perma.cc/B2YB-JB59 ↩
-
Dmitry Baranchuk, Artem Babenko, and Yury Malkov. Revisiting the Inverted Indices for Billion-Scale Approximate Nearest Neighbors. At European Conference on Computer Vision (ECCV), pages 202–216, September 2018. doi:10.1007/978-3-030-01258-8_13 ↩
-
Yury A. Malkov and Dmitry A. Yashunin. Efficient and robust approximate nearest neighbor search using Hierarchical Navigable Small World graphs. IEEE Transactions on Pattern Analysis and Machine Intelligence, volume 42, issue 4, pages 824–836, April 2020. doi:10.1109/TPAMI.2018.2889473 ↩