分片
显然,我们必须摆脱顺序限制,不要限制计算机。我们必须明确定义,并提供数据的优先级和描述。我们必须陈述关系,而不是程序。
格蕾丝·穆雷·霍普,未来的管理与计算机(1962)
分布式数据库通常通过两种方式在节点之间分配数据:
在多个节点上拥有相同数据的副本:这就是复制,我们在第六章中讨论过。
如果我们不希望每个节点存储所有数据,我们可以将大量数据拆分成更小的分片或分区,并将不同的分片存储在不同的节点上。我们将在本章讨论分片。
通常,分片的定义方式是每个数据片段(每条记录、行或文档)只属于一个分片。实现这一点的方法有多种,我们将在本章深入讨论。实际上,每个分片都是一个独立的小型数据库,尽管某些数据库系统支持同时操作多个分片。
分片通常与复制结合使用,以便每个分片的副本存储在多个节点上。这意味着,尽管每条记录只属于一个分片,但它仍然可以存储在多个不同的节点上以实现容错。
一个节点可以存储多个分片。如果使用单主复制模型,分片和复制的组合可以如图 7-1 所示。例如,每个分片的主节点被分配给一个节点,而其从节点被分配给其他节点。每个节点可以是某些分片的主节点,同时也是其他分片的从节点,但每个分片仍然只有一个主节点。
 图 7-1. 结合复制和分片:每个节点在某些分片中充当领导者,而在其他分片中充当跟随者。
图 7-1. 结合复制和分片:每个节点在某些分片中充当领导者,而在其他分片中充当跟随者。
我们在第 6 章中讨论的关于数据库复制的内容同样适用于分片的复制。由于分片方案的选择与复制方案的选择大多是独立的,因此为了简化起见,我们将在本章中忽略复制。
分片和分区
在本章中我们所称的分片,根据您使用的软件的不同,有许多不同的名称:在 Kafka 中称为分区,在 CockroachDB 中称为范围,在 HBase 和 TiDB 中称为区域,在 Bigtable 和 YugabyteDB 中称为平板,在 Cassandra、ScyllaDB 和 Riak 中称为 vnode,在 Couchbase 中称为 vBucket,仅举几例。
一些数据库将分区和分片视为两个不同的概念。例如,在 PostgreSQL 中,分区是一种将大表拆分为存储在同一台机器上的多个文件的方法(这有几个优点,例如可以非常快速地删除整个分区),而分片则是将数据集分布在多台机器上 12。在许多其他系统中,分区只是分片的另一种说法。
虽然分区这个术语相当直观,但分片这个术语可能令人惊讶。根据一种理论,这个术语源于在线角色扮演游戏《终极在线》,在游戏中,一个魔法水晶被打碎成碎片,每个碎片都折射出游戏世界的一个副本3。因此,shard 这个术语逐渐意味着一组并行游戏服务器中的一个,后来被引入到数据库中。另一种理论认为,shard 最初是“高度可用复制数据系统”(System for Highly Available Replicated Data)的缩写——据说这是一个 1980 年代的数据库,具体细节已失传。
顺便提一下,分区与网络分区(netsplits)无关,后者是一种节点之间网络故障。我们将在[即将到来的链接]中讨论此类故障。
分片的优缺点
分片数据库的主要原因是可扩展性:当数据量或写入吞吐量变得过于庞大,无法由单个节点处理时,分片是一种解决方案,因为它允许您将数据和写入分散到多个节点上。(如果问题出在读取吞吐量上,您不一定需要分片——您可以使用第 6 章中讨论的读取扩展。)
实际上,分片是我们实现横向扩展(扩展架构)的主要工具之一,如“共享内存、共享磁盘和无共享架构”中所讨论的:即允许系统通过添加更多(较小的)机器来增加其容量,而不是迁移到更大的机器。如果您能够将工作负载划分,使每个分片处理大致相等的份额,那么您就可以将这些分片分配给不同的机器,以便并行处理它们的数据和查询。
虽然复制在小规模和大规模上都很有用,因为它能够实现容错和离线操作,但分片是一种重量级解决方案,主要适用于大规模。如果您的数据量和写入吞吐量足够小,可以在单台机器上处理(而且如今单台机器的处理能力很强!),通常最好避免分片,使用单片数据库。
推荐这样做的原因是,分片通常会增加复杂性:您通常需要通过选择一个分区键来决定将哪些记录放入哪个分片;所有具有相同分区键的记录都放在同一个分片中4。这个选择很重要,因为如果您知道记录所在的分片,访问记录是快速的,但如果您不知道分片,就必须在所有分片中进行低效的搜索,而分片方案也很难更改。
因此,分片通常适用于键值数据,您可以轻松按键进行分片,但对于关系数据则更困难,因为您可能希望通过二级索引进行搜索,或者连接可能分布在不同分片中的记录。我们将在“分片和二级索引”中进一步讨论这一点。
分片的另一个问题是,写操作可能需要在几个不同的分片中更新相关记录。虽然在单个节点上的事务是相当常见的(见第 8 章),但在多个分片之间确保一致性需要分布式事务。正如我们将在[链接待补充]中看到的,某些数据库提供分布式事务,但它们通常比单节点事务慢得多,可能成为整个系统的瓶颈,并且有些系统根本不支持它们。
一些系统甚至在单台机器上使用分片,通常为每个 CPU 核心运行一个单线程进程,以利用 CPU 中的并行性,或利用非均匀内存访问(NUMA)架构,其中某些内存银行离一个 CPU 比其他 CPU 更近5。例如,Redis、VoltDB 和 FoundationDB 为每个核心使用一个进程,并依赖分片在同一台机器的 CPU 核心之间分散负载6。
多租户的分片
软件即服务(SaaS)产品和云服务通常是多租户的,每个租户都是一个客户。多个用户可能在同一个租户上有登录,但每个租户都有一个与其他租户分开的自包含数据集。例如,在一个电子邮件营销服务中,每个注册的企业通常是一个单独的租户,因为一个企业的新闻通讯注册、投递数据等与其他企业是分开的。
有时会使用分片来实现多租户系统:要么每个租户被分配一个单独的分片,要么多个小租户可以被组合到一个更大的分片中。这些分片可能是物理上分开的数据库(我们之前在“嵌入式存储引擎”中提到过),或者是一个更大逻辑数据库的可单独管理部分7。使用分片进行多租户有几个优点:
资源隔离
如果一个租户执行了计算密集型操作,那么如果其他租户在不同的分片上运行,其他租户的性能受到影响的可能性就会降低。
权限隔离
如果您的访问控制逻辑中存在漏洞,那么如果这些租户的数据集物理上彼此分开存储,您意外地将一个租户的访问权限授予另一个租户的数据的可能性就会降低。
基于单元的架构
您可以不仅在数据存储层应用分片,还可以在运行应用程序代码的服务层进行分片。在基于单元的架构中,特定租户集的服务和存储被分组到一个自包含的单元中,不同的单元被设置为可以在很大程度上独立运行。这种方法提供了故障隔离:即一个单元中的故障仅限于该单元,其他单元中的租户不受影响 [ 8]。
每个租户的备份和恢复
单独备份每个租户的分片使得可以从备份中恢复租户的状态,而不影响其他租户,这在租户意外删除或覆盖重要数据时非常有用8。
合规性
数据隐私法规如 GDPR 赋予个人访问和删除存储关于他们的所有数据的权利。如果每个人的数据存储在一个单独的分片中,这就转化为对他们的分片进行简单的数据导出和删除操作9。
数据驻留
如果特定租户的数据需要存储在特定的司法管辖区以遵守数据驻留法律,区域感知数据库可以让您将该租户的分片分配到特定区域。
渐进式模式发布
模式迁移(在“文档模型中的模式灵活性”中讨论过)可以逐步推出,一次一个租户。这降低了风险,因为您可以在问题影响所有租户之前检测到它们,但在事务上执行可能会很困难10。
使用分片进行多租户管理的主要挑战是:
-
它假设每个单独的租户足够小,可以适应单个节点。如果情况并非如此,并且您有一个单个租户的规模过大,无法在一台机器上处理,您还需要在单个租户内进行分片,这又将我们带回到可扩展性分片的话题 [ 12]。
-
如果你有很多小租户,那么为每个租户创建一个单独的分片可能会产生过多的开销。你可以将几个小租户组合在一起形成一个更大的分片,但这样你就会面临如何在租户增长时将其从一个分片移动到另一个分片的问题。
-
如果你需要支持跨多个租户连接数据的功能,那么如果需要在多个分片之间连接数据,这些功能的实现将变得更加困难。
键值数据的分片
假设你有大量数据,并且想要进行分片。你如何决定将哪些记录存储在哪些节点上?
我们进行分片的目标是将数据和查询负载均匀地分布在各个节点上。如果每个节点都能公平地分担负载,那么——理论上——10 个节点应该能够处理 10 倍于单个节点的数据量和 10 倍的读写吞吐量(忽略复制)。此外,如果我们添加或移除一个节点,我们希望能够重新平衡负载,以便在添加时均匀分布在 11 个节点上,或在移除时均匀分布在剩下的 9 个节点上。
如果分片不公平,以至于某些分片的数据或查询比其他分片多,我们称之为倾斜。倾斜的存在使得分片的效果大大降低。在极端情况下,所有负载可能最终集中在一个分片上,这样 10 个节点中的 9 个处于空闲状态,而你的瓶颈就是那个唯一繁忙的节点。负载不成比例高的分片称为热分片或热点。如果有一个键的负载特别高(例如,社交网络中的名人),我们称之为热键。
因此,我们需要一个算法,该算法以记录的分区键为输入,并告诉我们该记录所在的分片。在键值存储中,分区键通常是键,或键的第一部分。在关系模型中,分区键可能是表中的某一列(不一定是其主键)。该算法需要能够进行再平衡,以缓解热点问题。
按键范围分片
一种分片方法是将一段连续的分区键范围(从某个最小值到某个最大值)分配给每个分片,就像纸质百科全书的卷册一样,如图 7-2 所示。在这个例子中,条目的分区键是其标题。如果您想查找特定标题的条目,可以通过找到包含您要查找的标题的键范围的卷册,轻松确定哪个分片包含该条目,从而从书架上选择正确的书。

键的范围不一定均匀分布,因为您的数据可能并不均匀分布。例如,在图 7-2 中,卷 1 包含以 A 和 B 开头的单词,而卷 12 包含以 T、U、V、W、X、Y 和 Z 开头的单词。仅仅按照字母表每两个字母一个卷的方式,会导致某些卷的大小远大于其他卷。为了均匀分配数据,分片边界需要适应数据。
分片边界可以由管理员手动选择,也可以由数据库自动选择。例如,Vitess(MySQL 的分片层)使用手动键范围分片;而 Bigtable、其开源等价物 HBase、MongoDB 中的基于范围的分片选项、CockroachDB、RethinkDB 和 FoundationDB 则使用自动变体6。YugabyteDB 提供手动和自动的表分割。
在每个分片内,键以排序的顺序存储(例如,在 B 树或 SSTables 中,如第 4 章所讨论的)。这有一个优点,即范围扫描很简单,您可以将键视为一个连接的索引,以便在一次查询中获取多个相关记录(参见“多维和全文索引”)。例如,考虑一个存储传感器网络数据的应用程序,其中键是测量的时间戳。在这种情况下,范围扫描非常有用,因为它们可以让您轻松获取,例如,某个月的所有读数。
键范围分片的一个缺点是,如果对附近键的写入很多,您可能会轻易得到一个热点分片。例如,如果键是时间戳,则分片对应于时间范围——例如,每个月一个分片。不幸的是,如果您在测量发生时将传感器的数据写入数据库,所有的写入最终都会进入同一个分片(这个月的分片),因此该分片可能会因写入过多而过载,而其他分片则处于闲置状态11。
为了避免传感器数据库中的这个问题,您需要使用其他元素而不是时间戳作为键的第一个元素。例如,您可以在每个时间戳前加上传感器 ID,这样键的排序就会首先按传感器 ID,然后按时间戳。假设您有许多传感器同时处于活动状态,写入负载将更均匀地分布在各个分片上。缺点是,当您想在时间范围内获取多个传感器的值时,现在需要为每个传感器执行单独的范围查询。
重新平衡按键范围分片的数据
当您首次设置数据库时,没有键范围可以拆分成分片。一些数据库,如 HBase 和 MongoDB,允许您在空数据库上配置一组初始分片,这称为预拆分。这要求您对键分布的外观有一些了解,以便您可以选择合适的键范围边界12。
随着数据量和写入吞吐量的增长,具有键范围分片的系统通过将现有分片拆分为两个或更多较小的分片来扩展,每个较小的分片持有原始分片键范围的连续子范围。生成的较小分片可以分布在多个节点上。如果大量数据被删除,您可能还需要将几个相邻的小分片合并为一个更大的分片。这个过程类似于 B 树的顶层所发生的情况(参见“B 树”)。
对于自动管理分片边界的数据库,分片拆分通常由以下因素触发:
-
分片达到配置的大小(例如,在 HBase 中,默认值为 10 GB),或者
-
在某些系统中,写入吞吐量持续高于某个阈值。因此,即使热分片存储的数据不多,也可能会进行拆分,以便更均匀地分配其写入负载。
键范围分片的一个优点是分片数量可以根据数据量进行调整。如果数据量很小,少量的分片就足够了,因此开销也很小;如果数据量巨大,则每个分片的大小限制在可配置的最大值内13。
这种方法的一个缺点是拆分分片是一项昂贵的操作,因为这需要将所有数据重写到新文件中,类似于日志结构存储引擎中的压缩。需要拆分的分片通常也是负载较高的分片,而拆分的成本可能会加重该负载,导致其过载的风险。
按键的哈希进行分片
如果您希望具有相近(但不同)分区键的记录被分组到同一个分片中,键范围分片是有用的;例如,这可能适用于时间戳。如果您不在乎分区键是否彼此接近(例如,如果它们是多租户应用程序中的租户 ID),一种常见的方法是先对分区键进行哈希,然后再将其映射到分片。
一个好的哈希函数能够将偏斜的数据转化为均匀分布。假设你有一个 32 位的哈希函数,它接受一个字符串。每当你给它一个新的字符串时,它会返回一个看似随机的数字,范围在 0 到 $2^32 - 1$ 之间。即使输入的字符串非常相似,它们的哈希值在这个数字范围内也是均匀分布的(但相同的输入总是产生相同的输出)。
对于分片目的,哈希函数不需要具备密码学强度:例如,MongoDB 使用 MD5,而 Cassandra 和 ScyllaDB 使用 Murmur3。许多编程语言内置了简单的哈希函数(因为它们用于哈希表),但它们可能不适合用于分片:例如,在 Java 的 Object.hashCode() 和 Ruby 的 Object#hash 中,相同的键在不同的进程中可能具有不同的哈希值,这使得它们不适合用于分片14。
哈希取模节点数
一旦你对密钥进行了哈希,如何选择将其存储在哪个分片中呢?也许你首先想到的是将哈希值对系统中的节点数量取模(在许多编程语言中使用 % 运算符)。例如,hash(key) % 10 将返回一个介于 0 和 9 之间的数字(如果我们将哈希写成十进制数字,hash % 10 将是最后一位数字)。如果我们有 10 个节点,编号为 0 到 9,这似乎是将每个密钥分配给节点的简单方法。
使用 mod N 方法的问题在于,如果节点数量 N 发生变化,大多数密钥必须从一个节点移动到另一个节点。图 7-3 显示了当你有三个节点并添加第四个节点时会发生什么。在重新平衡之前,节点 0 存储哈希为 0、3、6、9 等的密钥。添加第四个节点后,哈希为 3 的密钥移动到了节点 3,哈希为 6 的密钥移动到了节点 2,哈希为 9 的密钥移动到了节点 1,等等。
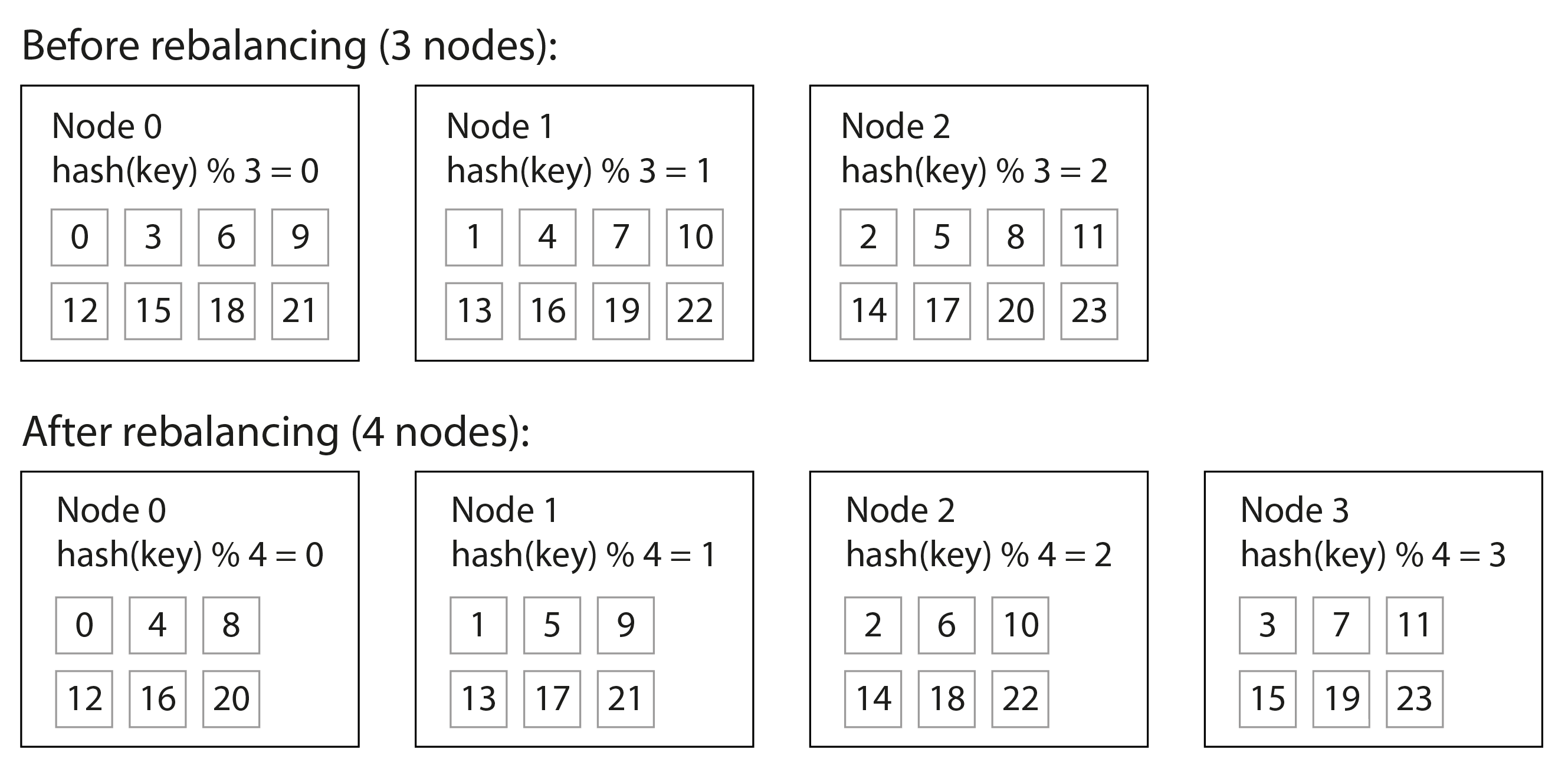
mod N 函数易于计算,但它导致非常低效的重新平衡,因为记录在节点之间的移动过于频繁。我们需要一种方法,尽量减少数据的移动。
固定数量的分片
一个简单但广泛使用的解决方案是创建比节点数量多得多的分片,并将多个分片分配给每个节点。例如,运行在 10 个节点集群上的数据库可以从一开始就拆分成 1,000 个分片,以便每个节点分配 100 个分片。然后,键存储在分片编号 hash(key) % 1,000 中,系统单独跟踪每个分片存储在哪个节点上。
现在,如果向集群中添加一个节点,系统可以将一些分片从现有节点重新分配到新节点,直到它们再次公平分布。这个过程在图 7-4 中进行了说明。如果从集群中移除一个节点,反向操作也会发生。
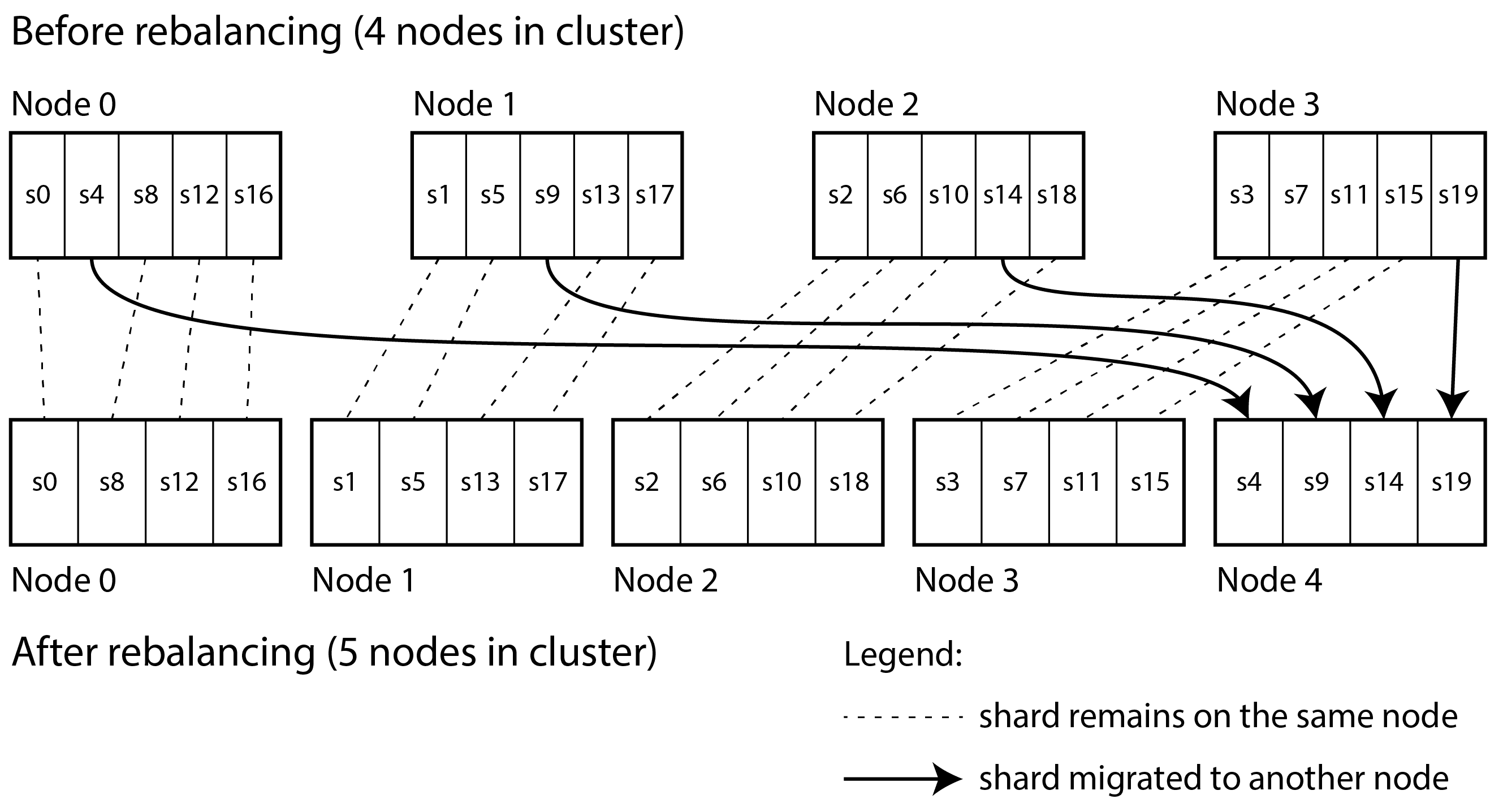
在此模型中,仅在节点之间移动整个分片,这比拆分分片更便宜。分片的数量不变,分片的键分配也不变。唯一改变的是分片与节点的分配。这种分配的变化不是立即的——在网络上转移大量数据需要一些时间——因此在传输进行时,旧的分片分配将用于任何读取和写入操作。
通常选择的分片数量是一个可以被多个因子整除的数字,以便数据集可以在不同数量的节点之间均匀分配——例如,不要求节点数量是 2 的幂4。您甚至可以考虑集群中硬件的不匹配:通过将更多的分片分配给更强大的节点,您可以使这些节点承担更大的负载。
这种分片方法在 Citus(PostgreSQL 的分片层)、Riak、Elasticsearch 和 Couchbase 等系统中得到了应用。只要在首次创建数据库时对所需的分片数量有一个良好的估计,这种方法就能很好地工作。然后,您可以轻松地添加或删除节点,但有一个限制,即节点的数量不能超过分片的数量。
如果您发现最初配置的分片数量不正确——例如,如果您已经达到需要比现有分片更多节点的规模——那么就需要进行昂贵的重新分片操作。它需要拆分每个分片并将其写入新文件,在此过程中使用大量额外的磁盘空间。一些系统不允许在同时写入数据库时进行重新分片,这使得在不发生停机的情况下更改分片数量变得困难。
选择合适的分片数量是困难的,特别是当数据集的总大小变化很大时(例如,数据集开始时很小,但可能会随着时间的推移变得更大)。由于每个分片包含总数据的固定比例,因此每个分片的大小会与集群中的总数据量成比例增长。如果分片非常大,重新平衡和从节点故障中恢复的成本会很高。但如果分片太小,则会产生过多的开销。最佳性能是在分片大小“恰到好处”时实现的,既不太大也不太小,但如果分片数量固定而数据集大小变化,这一点很难实现。
按哈希范围分片
如果所需的分片数量无法提前预测,最好使用一种能够轻松适应工作负载的分片方案。上述的键范围分片方案具有这一特性,但在对相邻键进行大量写入时存在热点风险。一种解决方案是将键范围分片与哈希函数结合,使每个分片包含一系列哈希值,而不是一系列键。
图 7-5 展示了一个使用 16 位哈希函数的示例,该函数返回一个介于 0 和 65,535 之间的数字 = $2^16 − 1$(实际上,哈希通常为 32 位或更高)。即使输入键非常相似(例如,连续的时间戳),它们的哈希值在该范围内也是均匀分布的。然后,我们可以为每个分片分配一系列哈希值:例如,将 0 到 16,383 的值分配给分片 0,将 16,384 到 32,767 的值分配给分片 1,依此类推。

与键范围分片类似,当哈希范围分片变得过大或负载过重时,可以对其进行拆分。这仍然是一个昂贵的操作,但可以根据需要进行,因此分片的数量会根据数据量的变化而调整,而不是事先固定。
与键范围分片相比,缺点在于对分区键的范围查询效率不高,因为范围内的键现在分散在所有分片中。然而,如果键由两列或更多列组成,并且分区键仅是这些列中的第一列,您仍然可以对第二列及后续列执行高效的范围查询:只要范围查询中的所有记录具有相同的分区键,它们就会在同一个分片中。
数据仓库中的分区和范围查询
像 BigQuery、Snowflake 和 Delta Lake 这样的数据仓库支持类似的索引方法,尽管术语有所不同。例如,在 BigQuery 中,分区键决定了记录所在的分区,而“集群列”决定了记录在分区内的排序方式。Snowflake 自动将记录分配到“微分区”,但允许用户为表定义集群键。Delta Lake 支持手动和自动分区分配,并支持集群键。对数据进行聚类不仅可以提高范围扫描性能,还可以改善压缩和过滤性能。
哈希范围分片在 YugabyteDB 和 DynamoDB 中使用15,并且在 MongoDB 中也是一个选项。Cassandra 和 ScyllaDB 使用这种方法的变体,如图 7-6 所示:哈希值的空间被分割成多个范围,范围的数量与节点的数量成比例(图 7-6 中每个节点 3 个范围,但 Cassandra 的默认值是每个节点 8 个,ScyllaDB 是每个节点 256 个),这些范围之间有随机边界。这意味着某些范围比其他范围大,但通过每个节点拥有多个范围,这些不平衡往往会得到平衡1316。
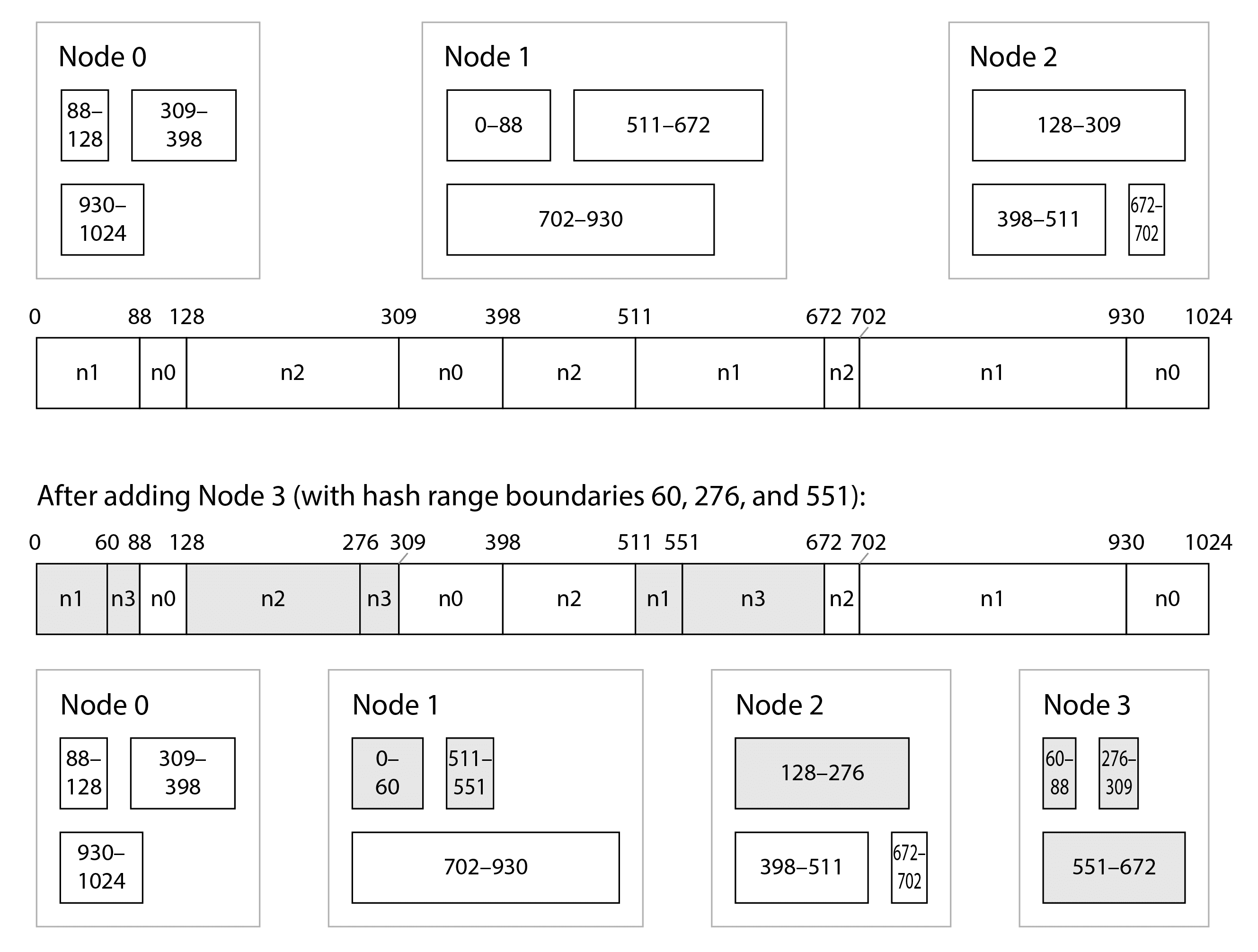
当节点被添加或移除时,范围边界也会相应地添加和移除,分片会相应地拆分或合并17。在图 7-6 的例子中,当节点 3 被添加时,节点 1 将其两个范围的一部分转移给节点 3,节点 2 将其一个范围的一部分转移给节点 3。这使得新节点获得了大致公平的数据集份额,而不需要从一个节点向另一个节点转移超过必要的数据。
一致性哈希
一致性哈希算法是一种哈希函数,它将键映射到指定数量的分片,满足两个属性:
-
映射到每个分片的键的数量大致相等,并且
-
当分片数量发生变化时,尽可能少的键从一个分片移动到另一个分片。
请注意,这里的“一致性”与副本一致性(见第 6 章)或 ACID 一致性(见第 8 章)无关,而是描述了一个键尽可能保持在同一分片中的倾向。
Cassandra 和 ScyllaDB 使用的分片算法类似于一致性哈希的原始定义18,但也提出了其他几种一致性哈希算法19,例如最高随机权重,也称为会合哈希[rendezvous hashing]20,以及跳跃一致性哈希[jump consistent hash]21。在 Cassandra 的算法中,如果添加一个节点,少量现有分片会被拆分为子范围;另一方面,在会合哈希和跳跃一致性哈希中,新节点被分配到之前分散在所有其他节点上的单独键。哪个更可取取决于应用程序。
倾斜的工作负载和缓解热点
一致性哈希确保键在节点之间均匀分布,但这并不意味着实际负载也均匀分布。如果工作负载高度倾斜——即某些分区键下的数据量远大于其他键,或者某些键的请求速率远高于其他键——你仍然可能会遇到一些服务器过载,而其他服务器几乎闲置的情况。
例如,在一个社交媒体网站上,一位拥有数百万粉丝的名人用户在做某件事情时可能会引发一阵活动22。这个事件可能导致对同一个键的大量读写(其中分区键可能是名人的用户 ID,或者是人们评论的动作的 ID)。
在这种情况下,需要更灵活的分片策略2324。一个基于键范围(或哈希范围)定义分片的系统使得可以将一个单独的热键放入一个分片中,甚至可能为其分配一台专用机器25。
在应用层面上也可以补偿倾斜。例如,如果一个键被认为是非常热门的,一个简单的技巧是在键的开头或结尾添加一个随机数字。仅仅是一个两位数的十进制随机数字就可以将对该键的写入均匀分配到 100 个不同的键上,从而允许这些键分布到不同的分片中。
然而,既然写入已经分散到不同的键上,任何读取现在都需要额外的工作,因为它们必须从所有 100 个键中读取数据并进行合并。对热门键的每个分片的读取量并没有减少;只有写入负载被分散。这个技巧还需要额外的记账:仅对少量热门键附加随机数字是有意义的;对于绝大多数写入吞吐量低的键,这将是多余的开销。因此,您还需要某种方式来跟踪哪些键正在被分割,以及将常规键转换为特别管理的热门键的过程。
随着时间的推移,负载变化进一步加剧了这个问题:例如,一条特定的社交媒体帖子可能会在几天内经历高负载,但之后很可能会再次平静下来。此外,一些键在写入时可能会很热,而另一些在读取时则会很热,这就需要采用不同的策略来处理它们。
一些系统(特别是为大规模设计的云服务)有自动化的方法来处理热分片;例如,亚马逊称之为热管理26 或自适应容量15。这些系统的工作细节超出了本书的范围。
操作:自动或手动重新平衡
关于重新平衡,有一个重要的问题我们尚未提及:分片和重新平衡是自动进行还是手动进行?
一些系统会自动决定何时拆分分片以及何时将其从一个节点移动到另一个节点,而无需任何人工干预,而其他系统则将分片的配置留给管理员显式设置。还有一种折中方案:例如,Couchbase 和 Riak 会自动生成建议的分片分配,但需要管理员在生效之前进行确认。
完全自动化的负载均衡可以很方便,因为正常维护的操作工作量较少,这样的系统甚至可以自动扩展以适应工作负载的变化。像 DynamoDB 这样的云数据库被宣传为能够在几分钟内自动添加和移除分片,以适应负载的大幅增加或减少 1527。
然而,自动分片管理也可能是不可预测的。重新平衡是一项昂贵的操作,因为它需要重新路由请求并将大量数据从一个节点移动到另一个节点。如果不小心进行,这个过程可能会使网络或节点过载,并可能损害其他请求的性能。在重新平衡进行时,系统必须继续处理写入;如果系统接近其最大写入吞吐量,分片拆分过程甚至可能无法跟上进入写入的速度27。
这种自动化与自动故障检测结合使用时可能是危险的。例如,假设一个节点过载并暂时响应请求缓慢。其他节点得出结论认为过载节点已经死掉,并自动重新平衡集群以将负载转移开。这给其他节点和网络带来了额外的负担,使情况变得更糟。存在导致级联故障的风险,其他节点也会过载,并被错误地怀疑为宕机。
因此,在重新平衡时有一个人参与可能是件好事。这比完全自动化的过程要慢,但可以帮助防止操作上的意外。
请求路由
我们已经讨论了如何在多个节点之间对数据集进行分片,以及如何在添加或移除节点时重新平衡这些分片。现在让我们继续讨论一个问题:如果你想读取或写入特定的键,你如何知道需要连接哪个节点——即哪个 IP 地址和端口号?
我们称这个问题为请求路由,它与我们之前在“负载均衡器、服务发现和服务网格”中讨论的服务发现非常相似。两者之间最大的区别在于,运行应用程序代码的服务通常是无状态的,负载均衡器可以将请求发送到任何实例。而对于分片数据库,针对某个键的请求只能由包含该键的分片的副本节点处理。
这意味着请求路由必须了解键到分片的分配,以及分片到节点的分配。从高层次来看,解决这个问题有几种不同的方法(如图 7-7 所示):
-
允许客户端联系任何节点(例如,通过轮询负载均衡器)。如果该节点恰好拥有请求所适用的分片,它可以直接处理请求;否则,它将请求转发到适当的节点,接收回复,并将回复传递给客户端。
-
首先将所有来自客户端的请求发送到路由层,该层确定应该处理每个请求的节点并相应地转发。该路由层本身不处理任何请求;它仅充当一个了解分片的负载均衡器。
-
要求客户端了解分片及分片与节点的分配。在这种情况下,客户端可以直接连接到适当的节点,而无需任何中介。
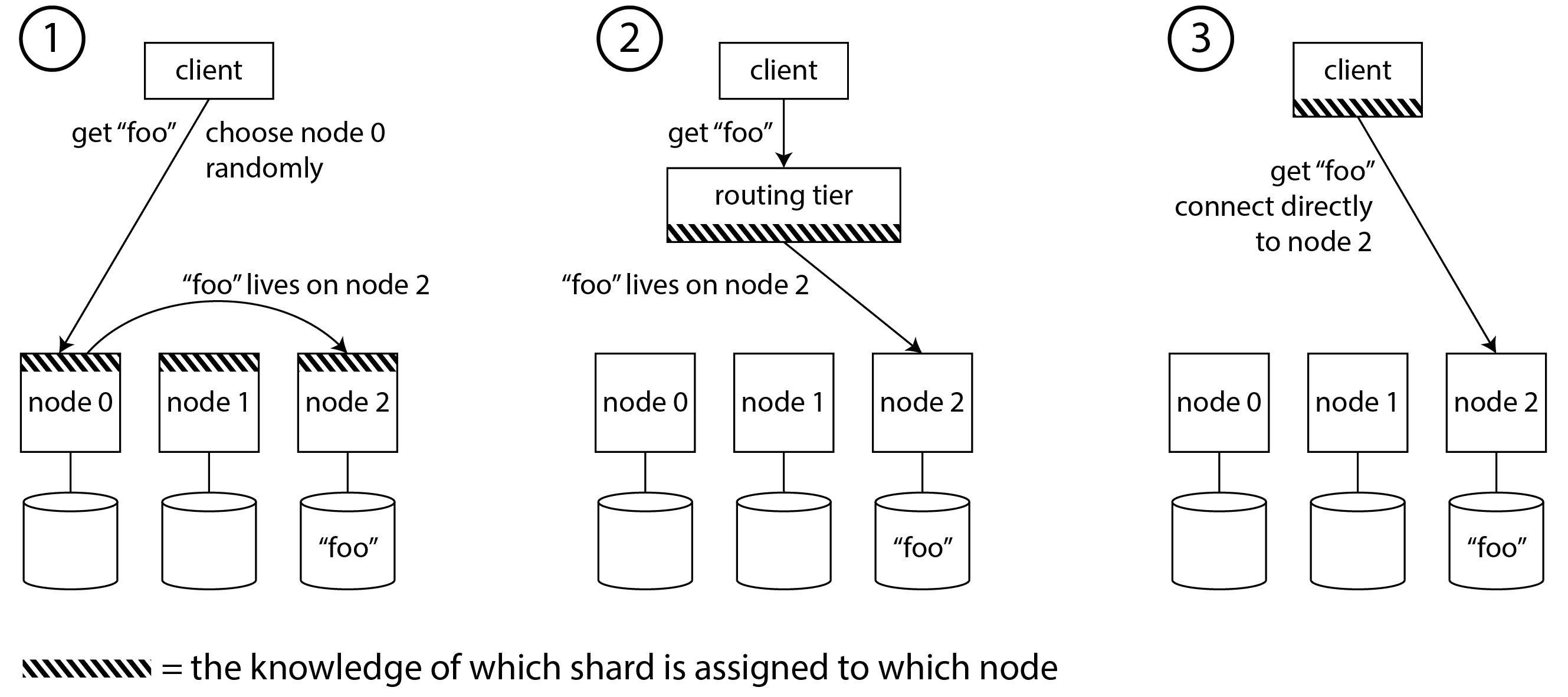
在所有情况下,都存在一些关键问题:
-
谁来决定哪个分片应该驻留在哪个节点上?由一个单一的协调者来做这个决定是最简单的,但在这种情况下,如果运行协调者的节点出现故障,如何确保其容错性?如果协调者角色可以切换到另一个节点,如何防止出现脑裂情况(参见“处理节点故障”),即两个不同的协调者做出相互矛盾的分片分配?
-
执行路由的组件(可能是某个节点、路由层或客户端)如何得知分片到节点的分配变化?
-
在一个分片从一个节点移动到另一个节点的过程中,会有一个切换期,此时新节点已经接管,但对旧节点的请求可能仍在进行中。你如何处理这些请求?
许多分布式数据系统依赖于像 ZooKeeper 或 etcd 这样的独立协调服务来跟踪分片分配,如图 7-8 所示。它们使用共识算法(见[链接待补充])来提供容错能力和防止脑裂的保护。每个节点在 ZooKeeper 中注册自己,ZooKeeper 维护着分片到节点的权威映射。其他参与者,如路由层或感知分片的客户端,可以订阅 ZooKeeper 中的这些信息。每当分片的所有权发生变化,或节点被添加或移除时,ZooKeeper 会通知路由层,以便它可以保持其路由信息的最新状态。
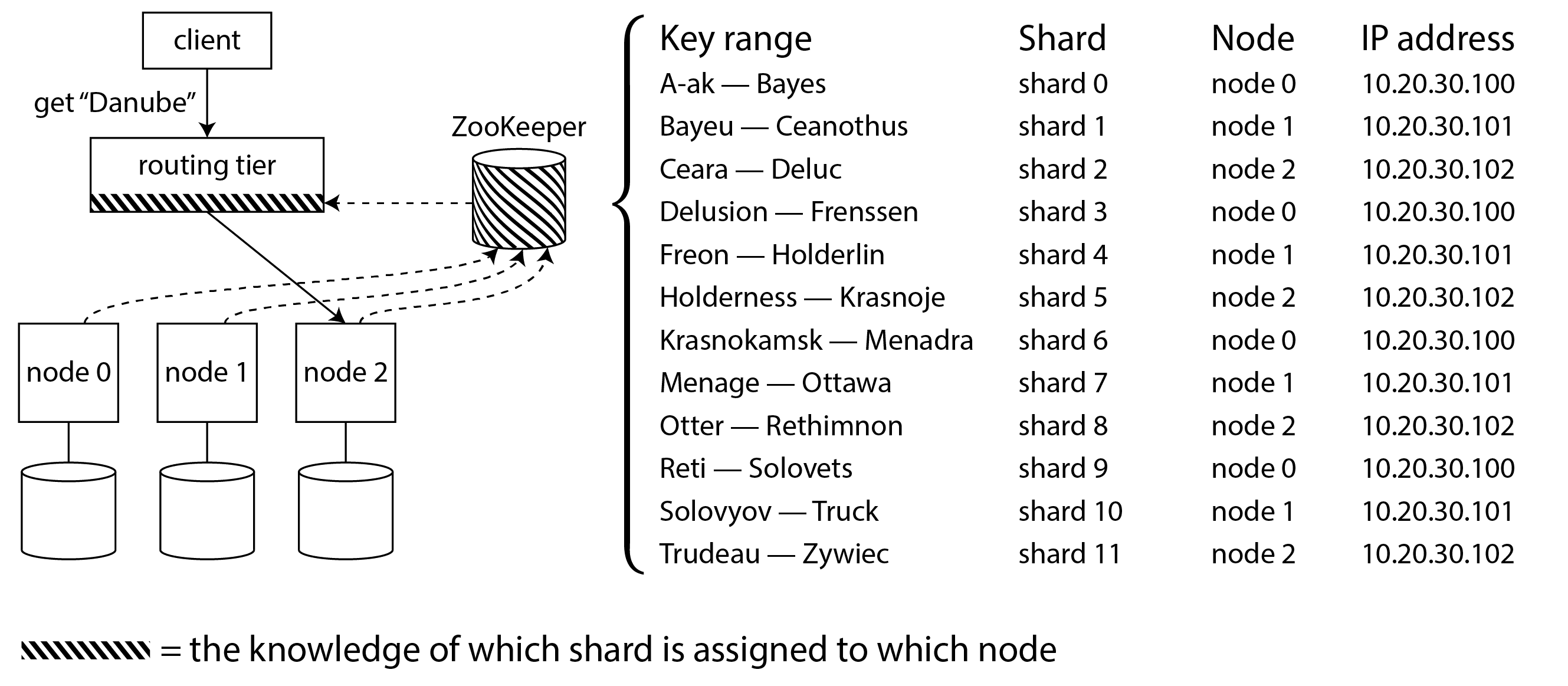
例如,HBase 和 SolrCloud 使用 ZooKeeper 来管理分片分配,而 Kubernetes 使用 etcd 来跟踪哪个服务实例在何处运行。MongoDB 有类似的架构,但它依赖于自己的配置服务器实现和 mongos 守护进程作为路由层。Kafka、YugabyteDB 和 TiDB 使用 Raft 共识协议的内置实现来执行这一协调功能。
Cassandra、ScyllaDB 和 Riak 采取了不同的方法:它们在节点之间使用一种 gossip 协议来传播集群状态的任何变化。这提供的强一致性远不如共识协议;可能会出现分脑现象,即集群的不同部分对同一分片有不同的节点分配。无领导数据库可以容忍这种情况,因为它们通常提供的弱一致性保证(参见“法定一致性的局限性”)。
在使用路由层或向随机节点发送请求时,客户端仍然需要找到要连接的 IP 地址。这些地址的变化没有分片到节点的分配那么快,因此通常使用 DNS 来满足这个目的就足够了。
关于请求路由的讨论集中在为单个键找到分片,这对于分片的 OLTP 数据库最为相关。分析型数据库通常也使用分片,但它们的查询执行方式通常非常不同:查询通常需要并行地聚合和连接来自许多不同分片的数据,而不是在单个分片中执行。我们将在[Link to Come]中讨论这种并行查询执行的技术。
分片和二级索引
我们迄今讨论的分片方案依赖于客户端知道其想要访问的任何记录的分区键。这在键值数据模型中最容易实现,其中分区键是主键的第一部分(或整个主键),因此我们可以使用分区键来确定分片,从而将读写路由到负责该键的节点。
如果涉及到二级索引,情况会变得更加复杂(另见“多列和二级索引”)。二级索引通常并不能唯一标识一条记录,而是一种搜索特定值出现的方式:查找用户 123 的所有操作,查找包含单词 hogwash 的所有文章,查找颜色为 red 的所有汽车,等等。
键值存储通常没有二级索引,但它们是关系数据库的基础,在文档数据库中也很常见,并且是全文搜索引擎(如 Solr 和 Elasticsearch)的存在理由。二级索引的问题在于它们无法与分片完美映射。对具有二级索引的数据库进行分片主要有两种方法:本地索引和全局索引。
本地二级索引
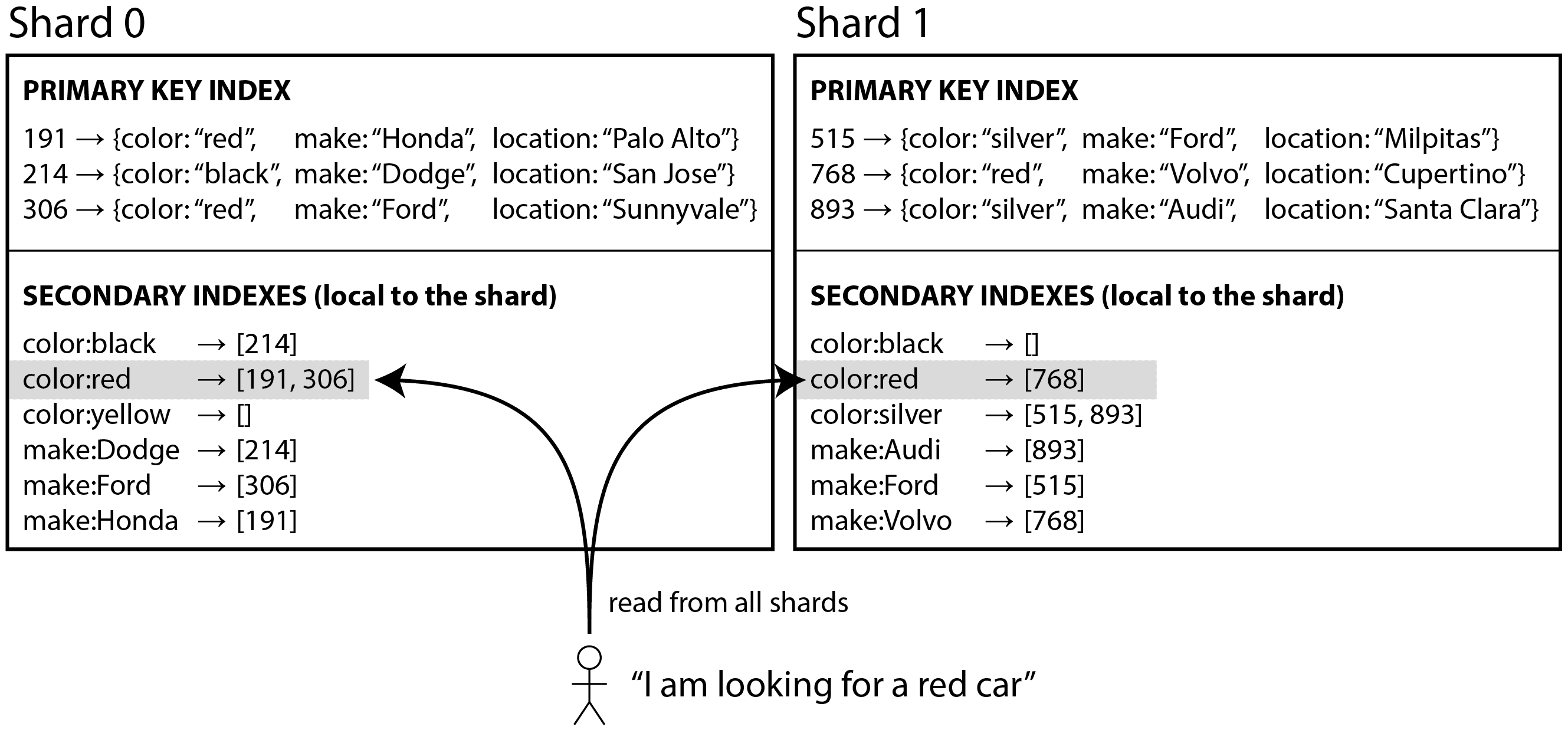
例如,假设您正在运营一个出售二手车的网站(如图 7-9 所示)。每个列表都有一个唯一的 ID,您使用该 ID 作为分片的分区键(例如,ID 0 到 499 在分片 0 中,ID 500 到 999 在分片 1 中,等等)。
如果您想让用户搜索汽车,并允许他们按颜色和品牌进行筛选,您需要在 color 和 make 上创建一个辅助索引(在文档数据库中,这些将是字段;在关系数据库中,它们将是列)。如果您已经声明了索引,数据库可以自动执行索引。例如,每当一辆红色汽车被添加到数据库时,数据库分片会自动将其 ID 添加到索引条目 color:red 的 ID 列表中。如第 4 章所讨论的,该 ID 列表也称为发布列表。
警告
如果您的数据库仅支持键值模型,您可能会想通过在应用程序代码中创建值到 ID 的映射来自己实现辅助索引。如果您选择这条路线,您需要非常小心,以确保您的索引与底层数据保持一致。竞争条件和间歇性写入失败(某些更改已保存但其他更改未保存)很容易导致数据不同步——请参见“多对象事务的必要性”。
在这种索引方法中,每个分片是完全独立的:每个分片维护自己的二级索引,仅覆盖该分片中的记录。它不关心其他分片中存储的数据。每当你向数据库写入数据——添加、删除或更新记录时——你只需处理包含你正在写入的记录的分片。因此,这种类型的二级索引被称为本地索引。在信息检索的上下文中,它也被称为文档分区索引28。
当从本地二级索引读取时,如果你已经知道要查找的记录的分区键,你可以直接在相应的分片上进行搜索。此外,如果你只想要一些结果,而不需要全部结果,你可以将请求发送到任何分片。
然而,如果你想要所有结果并且事先不知道它们的分区键,你需要将查询发送到所有分片,并合并你收到的结果,因为匹配的记录可能分散在所有分片中。在图 7-9 中,红色汽车出现在分片 0 和分片 1 中。
这种对分片数据库的查询方法可能会使对辅助索引的读取查询变得相当昂贵。即使你并行查询分片,它也容易导致尾延迟放大(参见“响应时间指标的使用”)。这也限制了你应用程序的可扩展性:添加更多的分片可以让你存储更多的数据,但如果每个分片都必须处理每个查询,那么它并不会增加你的查询吞吐量。
然而,本地辅助索引被广泛使用29:例如,MongoDB、Riak、Cassandra30、Elasticsearch31、SolrCloud 和 VoltDB32 都使用本地辅助索引。
全局辅助索引
与每个分片拥有自己的本地辅助索引不同,我们可以构建一个覆盖所有分片数据的全局索引。然而,我们不能仅仅将该索引存储在一个节点上,因为这可能会成为瓶颈,从而违背分片的目的。全局索引也必须进行分片,但它的分片方式可以与主键索引不同。
图 7-10 展示了这可能是什么样子:所有分片中红色汽车的 ID 出现在索引的 color:red 下,但索引是分片的,因此以字母 a 到 r 开头的颜色出现在分片 0 中,而以字母 s 到 z 开头的颜色出现在分片 1 中。汽车品牌的索引也以类似方式进行分区(分片边界在 f 和 h 之间)。
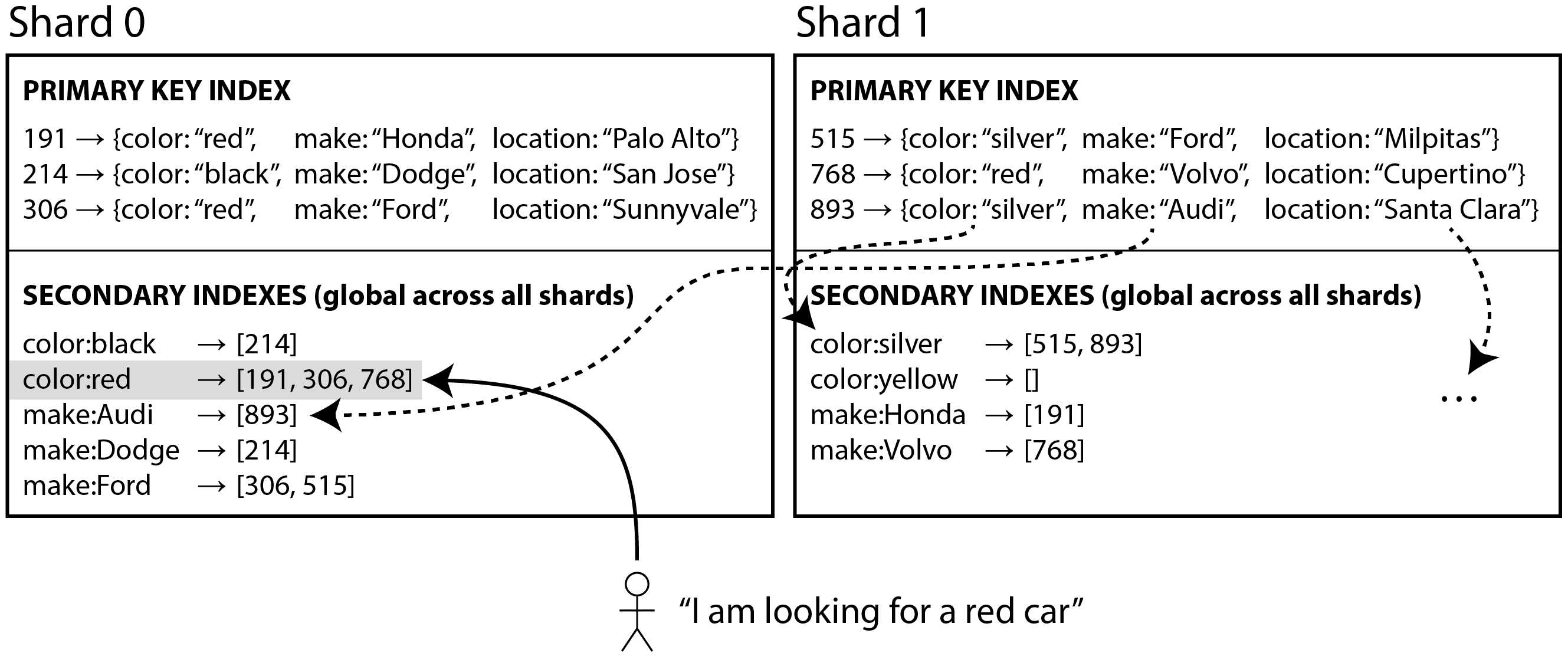
这种类型的索引也称为术语分区28:回想一下“全文搜索”,在全文搜索中,术语是您可以搜索的文本中的关键字。在这里,我们将其推广为指您可以在二级索引中搜索的任何值。
全局索引使用术语作为分区键,因此当您寻找特定术语或值时,您可以确定需要查询哪个分片。与之前一样,一个分片可以包含一系列连续的术语(如图 7-10 所示),或者您可以根据术语的哈希值将术语分配给分片。
全局索引的优点在于,带有单一条件的查询(例如,颜色 = 红色)只需从单个分片读取即可获取文档列表。然而,如果您想获取记录而不仅仅是 ID,您仍然需要从所有负责这些 ID 的分片中读取。
如果您有多个搜索条件或术语(例如,搜索某种颜色和某种品牌的汽车,或搜索在同一文本中出现的多个词),这些术语很可能会被分配到不同的分片。为了计算这两个条件的逻辑与,系统需要找到同时出现在两个文档列表中的所有 ID。如果文档列表较短,这没问题,但如果它们很长,发送它们以计算交集可能会很慢28。
另一个与全局二级索引相关的挑战是,写入操作比本地索引更复杂,因为写入单个记录可能会影响索引的多个分片(文档中的每个术语可能位于不同的分片上)。这使得保持二级索引与基础数据同步变得更加困难。一个选项是使用分布式事务原子性地更新存储主记录及其二级索引的分片(请参见第 8 章和[链接即将发布])。
CockroachDB、TiDB 和 YugabyteDB 使用全局二级索引;DynamoDB 支持本地和全局二级索引。在 DynamoDB 的情况下,写入操作会异步反映在全局索引中,因此从全局索引读取的数据可能是过时的(类似于复制延迟,如“复制延迟的问题”中所述)。尽管如此,如果读取吞吐量高于写入吞吐量,并且发布列表不太长,全局索引仍然是有用的。
总结
在本章中,我们探讨了将大型数据集分割成较小子集的不同方法。当数据量大到在单台机器上存储和处理变得不可行时,就需要进行分片。
分片的目标是将数据和查询负载均匀分布在多台机器上,避免热点(负载不成比例高的节点)。这需要选择适合您数据的分片方案,并在节点被添加到或从集群中移除时重新平衡分片。
我们讨论了两种主要的分片方法:
-
键范围分片,其中键被排序,一个分片拥有从某个最小值到某个最大值的所有键。排序的优点是可以进行高效的范围查询,但如果应用程序经常访问在排序顺序中相近的键,就存在热点的风险。
-
在这种方法中,当一个分片变得过大时,通常通过将范围分割成两个子范围来重新平衡分片。
-
哈希分片,其中对每个键应用哈希函数,并且一个分片拥有一系列哈希值(或者可以使用其他一致性哈希算法将哈希映射到分片)。这种方法破坏了键的顺序,使得范围查询效率低下,但可能会更均匀地分配负载。
-
当通过哈希进行分片时,通常会提前创建固定数量的分片,为每个节点分配几个分片,并在添加或移除节点时将整个分片从一个节点移动到另一个节点。像按键范围那样拆分分片也是可能的。
通常使用键的第一部分作为分区键(即识别分片),并根据其余的键对该分片内的记录进行排序。这样,您仍然可以在具有相同分区键的记录之间进行高效的范围查询。
我们还讨论了分片与二级索引之间的相互作用。二级索引也需要进行分片,方法有两种:
-
本地二级索引,其中二级索引与主键和值存储在同一个分片中。这意味着在写入时只需要更新一个分片,但查找二级索引时需要从所有分片中读取。
-
全局二级索引,基于索引值单独分片。二级索引中的一个条目可能引用主键的所有分片中的记录。当写入一条记录时,可能需要更新多个二级索引分片;然而,读取发布列表可以从单个分片提供(获取实际记录仍然需要从多个分片读取)。
最后,我们讨论了将查询路由到适当分片的技术,以及协调服务如何常常用于跟踪分片与节点的分配。
从设计上讲,每个分片大多独立运行——这使得分片数据库能够扩展到多个机器。然而,需要写入多个分片的操作可能会出现问题:例如,如果对一个分片的写入成功,但另一个失败,会发生什么?我们将在接下来的章节中解决这个问题。
参考文献
Footnotes
-
Claire Giordano. Understanding partitioning and sharding in Postgres and Citus. citusdata.com, August 2023. Archived at perma.cc/8BTK-8959 ↩
-
Brandur Leach. Partitioning in Postgres, 2022 edition. brandur.org, October 2022. Archived at perma.cc/Z5LE-6AKX ↩
-
Raph Koster. Database “sharding” came from UO? raphkoster.com, January 2009. Archived at perma.cc/4N9U-5KYF ↩
-
Garrett Fidalgo. Herding elephants: Lessons learned from sharding Postgres at Notion. notion.com, October 2021. Archived at perma.cc/5J5V-W2VX ↩ ↩2
-
Ulrich Drepper. What Every Programmer Should Know About Memory. akkadia.org, November 2007. Archived at perma.cc/NU6Q-DRXZ ↩
-
Jingyu Zhou, Meng Xu, Alexander Shraer, Bala Namasivayam, Alex Miller, Evan Tschannen, Steve Atherton, Andrew J. Beamon, Rusty Sears, John Leach, Dave Rosenthal, Xin Dong, Will Wilson, Ben Collins, David Scherer, Alec Grieser, Young Liu, Alvin Moore, Bhaskar Muppana, Xiaoge Su, and Vishesh Yadav. FoundationDB: A Distributed Unbundled Transactional Key Value Store. At ACM International Conference on Management of Data (SIGMOD), June 2021. doi:10.1145/3448016.3457559 ↩ ↩2
-
Marco Slot. Citus 12: Schema-based sharding for PostgreSQL. citusdata.com, July 2023. Archived at perma.cc/R874-EC9W ↩
-
Gwen Shapira. Things DBs Don’t Do - But Should. thenile.dev, February 2023. Archived at perma.cc/C3J4-JSFW ↩
-
Malte Schwarzkopf, Eddie Kohler, M. Frans Kaashoek, and Robert Morris. Position: GDPR Compliance by Construction. At Towards Polystores that manage multiple Databases, Privacy, Security and/or Policy Issues for Heterogenous Data (Poly), August 2019. doi:10.1007/978-3-030-33752-0_3 ↩
-
Gwen Shapira. Introducing pg_karnak: Transactional schema migration across tenant databases. thenile.dev, November 2024. Archived at perma.cc/R5RD-8HR9 ↩
-
Ikai Lan. App Engine Datastore Tip: Monotonically Increasing Values Are Bad. ikaisays.com, January 2011. Archived at perma.cc/BPX8-RPJB ↩
-
Enis Soztutar. Apache HBase Region Splitting and Merging. cloudera.com, February 2013. Archived at perma.cc/S9HS-2X2C ↩
-
Eric Evans. Rethinking Topology in Cassandra. At Cassandra Summit, June 2013. Archived at perma.cc/2DKM-F438 ↩ ↩2
-
Martin Kleppmann. Java’s hashCode Is Not Safe for Distributed Systems. martin.kleppmann.com, June 2012. Archived at perma.cc/LK5U-VZSN ↩
-
Mostafa Elhemali, Niall Gallagher, Nicholas Gordon, Joseph Idziorek, Richard Krog, Colin Lazier, Erben Mo, Akhilesh Mritunjai, Somu Perianayagam, Tim Rath, Swami Sivasubramanian, James Christopher Sorenson III, Sroaj Sosothikul, Doug Terry, and Akshat Vig. Amazon DynamoDB: A Scalable, Predictably Performant, and Fully Managed NoSQL Database Service. At USENIX Annual Technical Conference (ATC), July 2022. ↩ ↩2 ↩3
-
Brandon Williams. Virtual Nodes in Cassandra 1.2. datastax.com, December 2012. Archived at perma.cc/N385-EQXV ↩
-
Branimir Lambov. New Token Allocation Algorithm in Cassandra 3.0. datastax.com, January 2016. Archived at perma.cc/2BG7-LDWY ↩
-
David Karger, Eric Lehman, Tom Leighton, Rina Panigrahy, Matthew Levine, and Daniel Lewin. Consistent Hashing and Random Trees: Distributed Caching Protocols for Relieving Hot Spots on the World Wide Web. At 29th Annual ACM Symposium on Theory of Computing (STOC), May 1997. doi:10.1145/258533.258660 ↩
-
Damian Gryski. Consistent Hashing: Algorithmic Tradeoffs. dgryski.medium.com, April 2018. Archived at perma.cc/B2WF-TYQ8 ↩
-
David G. Thaler and Chinya V. Ravishankar. Using name-based mappings to increase hit rates. IEEE/ACM Transactions on Networking, volume 6, issue 1, pages 1–14, February 1998. doi:10.1109/90.663936 ↩
-
John Lamping and Eric Veach. A Fast, Minimal Memory, Consistent Hash Algorithm. arxiv.org, June 2014. ↩
-
Samuel Axon. 3% of Twitter’s Servers Dedicated to Justin Bieber. mashable.com, September 2010. Archived at perma.cc/F35N-CGVX ↩
-
Gerald Guo and Thawan Kooburat. Scaling services with Shard Manager. engineering.fb.com, August 2020. Archived at perma.cc/EFS3-XQYT ↩
-
Sangmin Lee, Zhenhua Guo, Omer Sunercan, Jun Ying, Thawan Kooburat, Suryadeep Biswal, Jun Chen, Kun Huang, Yatpang Cheung, Yiding Zhou, Kaushik Veeraraghavan, Biren Damani, Pol Mauri Ruiz, Vikas Mehta, and Chunqiang Tang. Shard Manager: A Generic Shard Management Framework for Geo-distributed Applications. 28th ACM SIGOPS Symposium on Operating Systems Principles (SOSP), pages 553–569, October 2021. doi:10.1145/3477132.3483546 ↩
-
Scott Lystig Fritchie. A Critique of Resizable Hash Tables: Riak Core & Random Slicing. infoq.com, August 2018. Archived at perma.cc/RPX7-7BLN ↩
-
Andy Warfield. Building and operating a pretty big storage system called S3. allthingsdistributed.com, July 2023. Archived at perma.cc/6S7P-GLM4 ↩
-
Rich Houlihan. DynamoDB adaptive capacity: smooth performance for chaotic workloads (DAT327). At AWS re:Invent, November 2017. ↩ ↩2
-
Christopher D. Manning, Prabhakar Raghavan, and Hinrich Schütze. Introduction to Information Retrieval. Cambridge University Press, 2008. ISBN: 978-0-521-86571-5, available online at nlp.stanford.edu/IR-book ↩ ↩2 ↩3
-
Michael Busch, Krishna Gade, Brian Larson, Patrick Lok, Samuel Luckenbill, and Jimmy Lin. Earlybird: Real-Time Search at Twitter. At 28th IEEE International Conference on Data Engineering (ICDE), April 2012. doi:10.1109/ICDE.2012.149 ↩
-
Nadav Har’El. Indexing in Cassandra 3. github.com, April 2017. Archived at perma.cc/3ENV-8T9P ↩
-
Zachary Tong. Customizing Your Document Routing. elastic.co, June 2013. Archived at perma.cc/97VM-MREN ↩
-
Andrew Pavlo. H-Store Frequently Asked Questions. hstore.cs.brown.edu, October 2013. Archived at perma.cc/X3ZA-DW6Z ↩